

Authors:
(1) Nir Chemaya, University of California, Santa Barbara and (e-mail: nir@ucsb.edu);
(2) Daniel Martin, University of California, Santa Barbara and Kellogg School of Management, Northwestern University and (e-mail: danielmartin@ucsb.edu).
Table of Links
- Abstract and Introduction
- Methods
- Results
- Discussion
- References
- Appendix for Perceptions and Detection of AI Use in Manuscript Preparation for Academic Journals
3 Results
3.1 Reporting Views and Detection Evaluations
Figure 1 presents the fraction of survey respondents who indicated that using ChatGPT to fix grammar or rewrite text should be acknowledged. We find substantial differences in reporting views between using ChatGPT for fixing grammar and using it to rewrite text, with 22% of the respondents indicating that grammar correction should be reported relative to 52% for text rewriting (a two-sided test of proportions gives p<0.0001). These perceptions were cleanly nested, as 95% of respondents who thought grammar should be reported also thought rewriting should be reported (only 3 respondents thought that fixing grammar should be reported but not rewriting.)
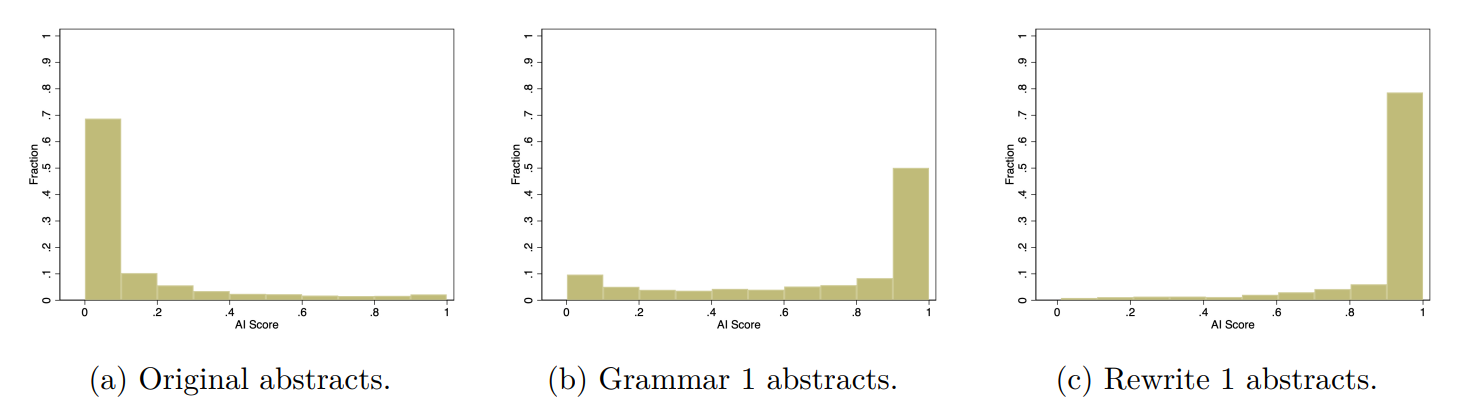
On aggregate, survey respondents viewed these types of AI use differently, but did the AI detector we study treat them differently? Figure 2 shows that the distribution of AI scores is skewed more to the right for abstracts revised using the Rewrite 1 prompt than for those revised using the Grammar 1 prompt. However, both Grammar 1 and Rewrite 1 produce a large number of high AI scores, and if we look again in Figure 1, the 75th percentile values of the AI scores for the abstracts produced by these two prompts are both near the maximal value. It is worth noting that while the detector gave abstracts revised using both prompts high scores, gave much lower scores to the original abstracts. Thus, it had a high degree of accuracy in separating manuscripts that were not revised by ChatGPT from those that were revised in some way.
However, this analysis does not indicate how Grammar 1 and Rewrite 1 compare for a given abstract. It could be that abstracts always had higher AI scores when the Rewrite 1 prompt was used. Looking at the abstract level, 2.2% of abstracts had the same AI score for both types of prompts and 24.2% of abstracts had an higher AI score when the Grammar 1 prompt was used than when the Rewrite 1 prompt was used.
These results combine to produce our first main finding:
Main Finding 3.1 The academics we surveyed were less likely to think that using AI to fix the grammar in manuscripts should be reported than using AI to rewrite manuscripts, but detection software did not always draw this distinction, as abstracts for which GPT-3.5 was used to fix grammar were often flagged as having a high chance of being written by AI.
3.2 Heterogeneity of Perceptions
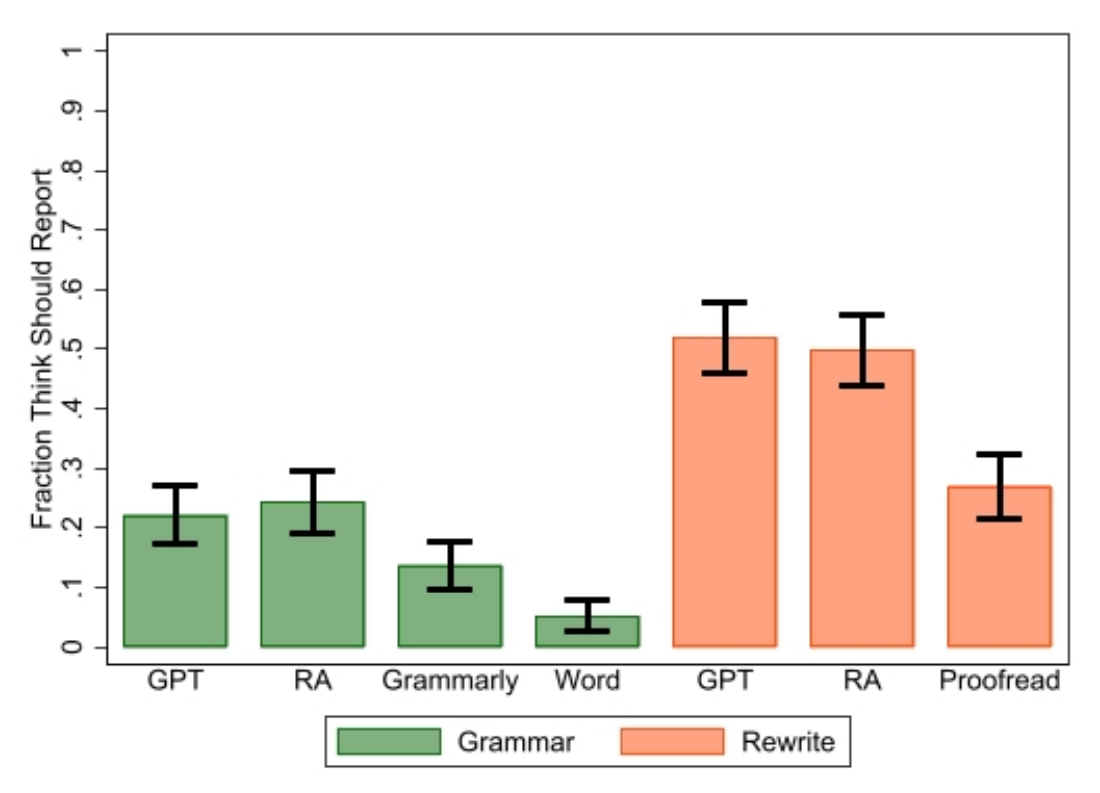
When we compare our survey results for different sources of assistance, we find very similar reporting preferences between ChatGPT and the help of a research assistant (RA) for grammar correction or for rewriting text, which is illustrated in Figure 2. More detailed summary statistics are provided in Appendix B. Comparing the difference between RA and ChatGPT for fixing grammar and rewriting text, we find no significant difference (p=0.5418 for fixing grammar and p=0.6062 for rewriting for two-sided tests of proportions).
However, respondents indicated that other tools used for fixing grammar, such as Grammarly and Word, should be acknowledged at even lower rates than ChatGPT, even though these tools might provide users with similar grammar corrections as ChatGPT. Only 14% (5%) of those completing the survey responded that researchers should report using Grammarly (Word) to fix grammar for academic text. A two-sided test of proportions between reporting ChatGPT and Grammarly (Word) for fixing grammar gives p=0.0100 (p<0.0001). This might indicate that researchers are unfamiliar with the differences between these tools, especially given that Grammarly uses some AI models (Fitria 2021). Alternatively, respondents may be so familiar with those tools that they are less worried about their influence on academic writing compared to ChatGPT, which is relatively new.
Finally, only 27% of those completing the survey responded that proofreading services should be acknowledged for rewriting academic text, which is much lower than for ChatGPT (52%) and for RA help (49.6%). A two-sided test of proportions comparing ChatGPT to proofreading for rewriting text gives p<0.0001. One explanation for this result could be that proofreading might be considered to be closer to fixing grammar than rewriting text (even that we explicitly stated that proofreading would be used for rewriting text). Another potential explanation could stem from an academic norm related to acknowledging this service or the fact that this service is paid.
This leads to our second main finding:
Main Finding 3.2 We found little difference in preferences for reporting ChatGPT and RA help, but significant differences in reporting preferences between these sources of assistance and paid proofreading and other AI assistant tools (Grammarly and Word).
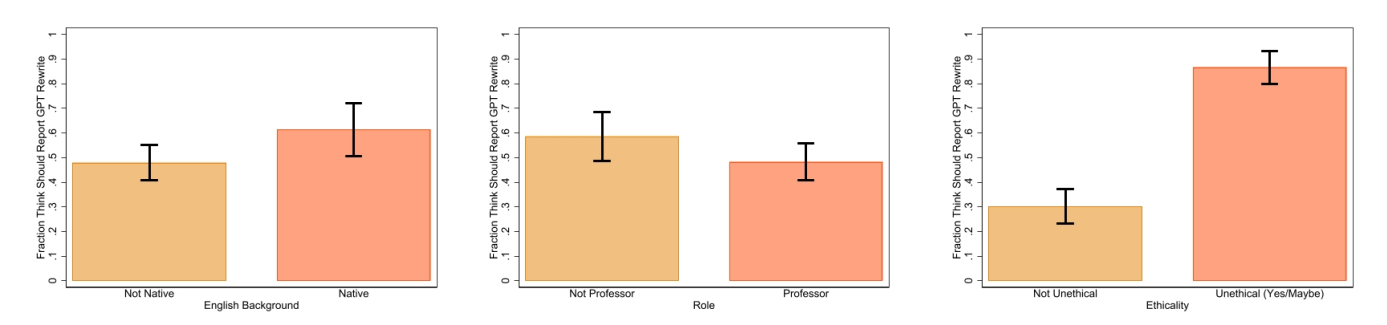
Next, we investigate the potential reasons why some academics we surveyed thought that using ChatGPT to rewrite text should be reported and why others did not. Figure 4 shows how reporting preferences differ by English language background (native speaker or not), academic role (professor or not), and perceptions of ethics (whether using ChatGPT to rewrite text is unethical or not). To increase statistical power, we collapse role into professor or not and pool together those who answered either “yes” or “maybe” to the survey question on the ethics of using ChatGPT to rewrite text. When we compare native English speakers to non-native ones, we find that on average native speakers are more inclined towards reporting the use of ChatGPT for rewriting text. When we compare professors (both tenured and untenured) to students and postdocs we find that, on average, postdocs and students are more likely to believe that authors should acknowledge the use of ChatGPT when rewriting text. One possible explanation is that early career researchers are more conservative because they are unfamiliar with the norms in the profession and prefer to take the safer option and report. On the other hand, they may have a better sense of the power of these tools, and hence might feel that reporting is more necessary. Finally, we find large differences in reporting preferences based on perceptions of ethics. Survey respondents who believe that it is unethical to use ChatGPT to rewrite text are almost three times more likely to believe that it should be reported. A more detailed analysis of perceptions of ethics is provided in Appendix B.
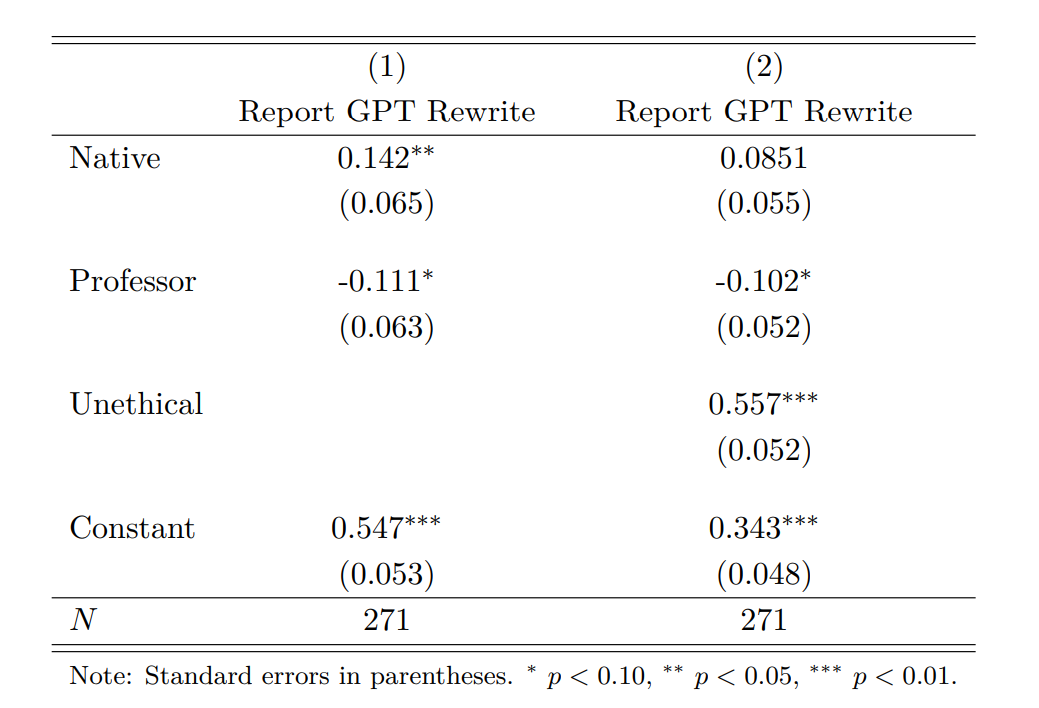
When we run an OLS regression analysis with only English language background (dummy variable Native=1) and academic role (dummy variable Professor=1) as the explanatory variables, as presented in first column of Table 2, we find that the coefficients are significant at the 5% and 10% level for Native and Professor respectively. However, when we add perceptions of ethics to the regression, the effect for Native becomes weaker and less significant. This suggests that some of this effect was due to differences in perceptions of ethics between native and non-native speakers of English.
Main Finding 3.3 We found disagreements among the academics we surveyed about whether using Chat-GPT to rewrite text needs to be reported, and differences were related to perceptions of ethics, academic role, and English language background.
3.3 Detection Robustness
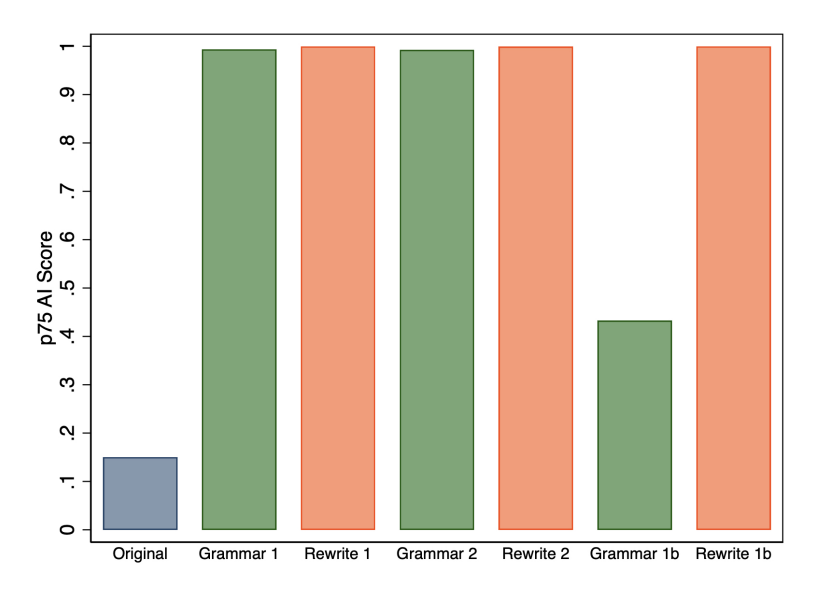
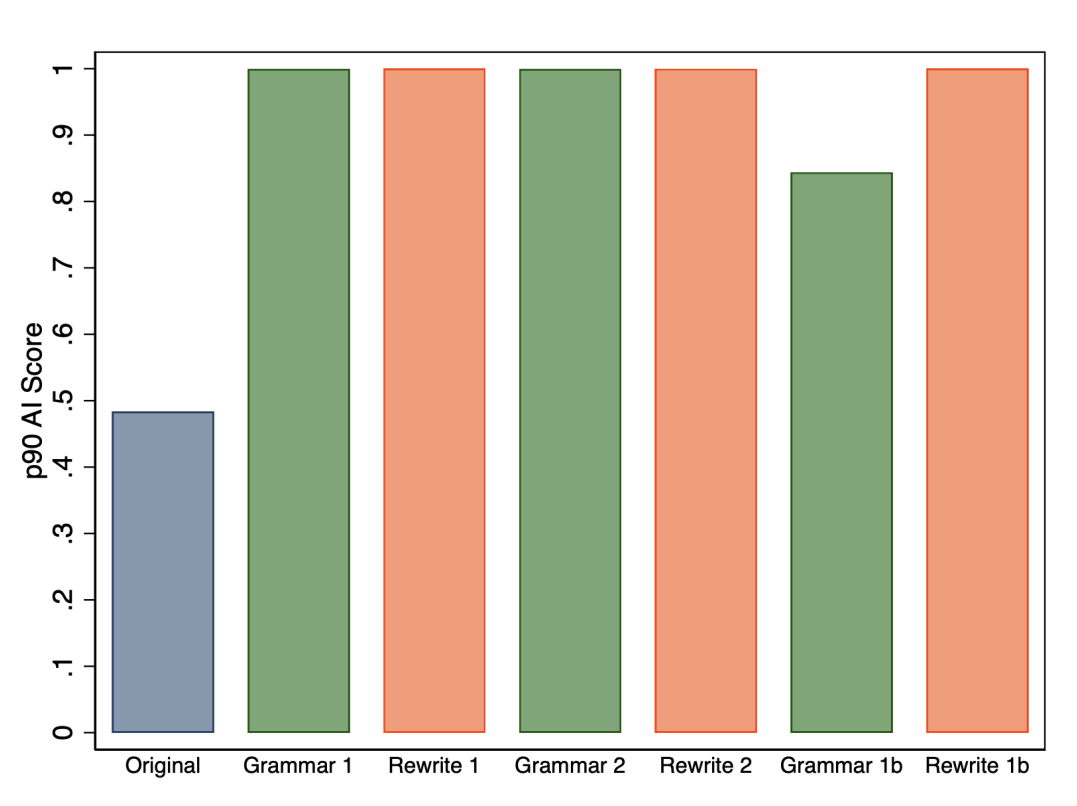
First, we compare the 75th percentile of AI scores across all of the prompts provided in Table 1, and Figure 5 shows that we find no perceptible differences for Grammar 2 and Rewrite 2. However, we find that dropping the requirement that the GPT-3.5 output be only one paragraph dramatically reduces the 75th percentile value when revising grammar (Grammar 1b). However, the result is more robust if we consider the 90th percentile instead, as shown in Figure 6.
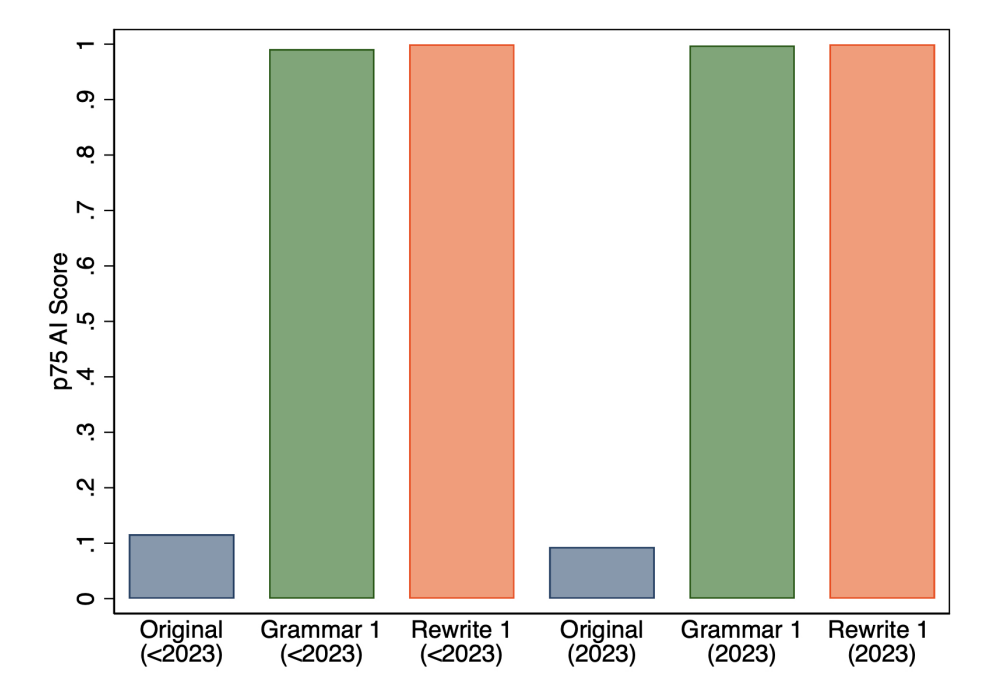
Second, we checked if the 75th percentile values of the AI scores were different in the years before and after the launch of ChatGPT. Looking at the 75th percentile of AI scores in Figure 7, we find a very slight decrease in the 75th percentile AI scores for original abstracts that appeared in 2023. Given this small change for original abstracts, it might not be surprisingly that we do not see much of a difference for Grammar 1 or Rewrite 1.
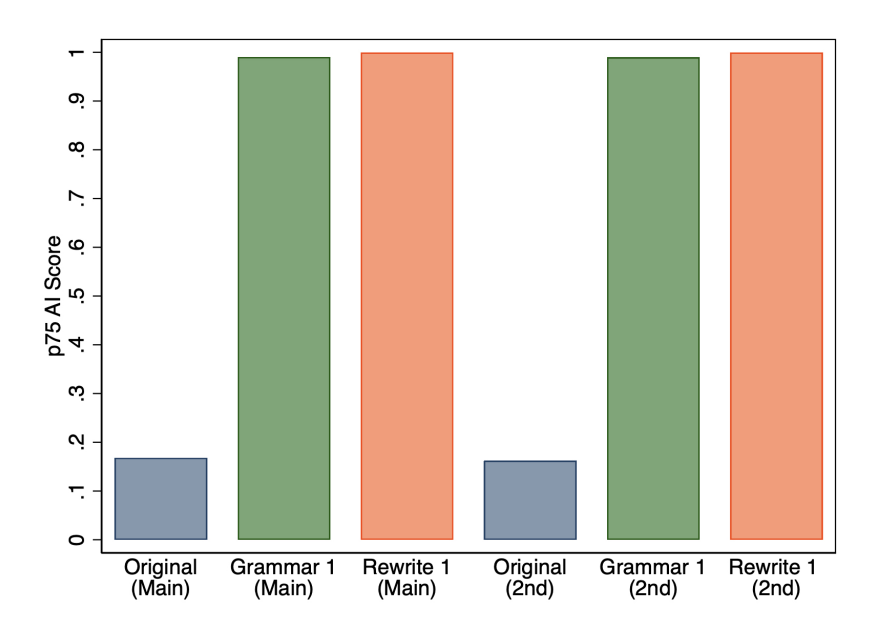
Third, we ran 1,016 of our abstracts through ChatGPT twice to test for the variability in AI scores due to any stochasticity in ChatGPT. Figure 8 shows that there is very little difference in the 75th percentile of scores.
This paper is available on arxiv under CC 4.0 license.