
In my previous article, you were introduced to Pub/Sub systems while focusing on Apache Kafka. You got to see the critical components of Kafka's architecture at a high level. Apache Kafka offers you three key features. It's the ability to publish & subscribe to events, store them, and process them in real time or later.
In this article, you'll better understand all the components that make these features possible. You'll go deeper into the internal components of the Apache Kafka architecture and how they work together.
Overview
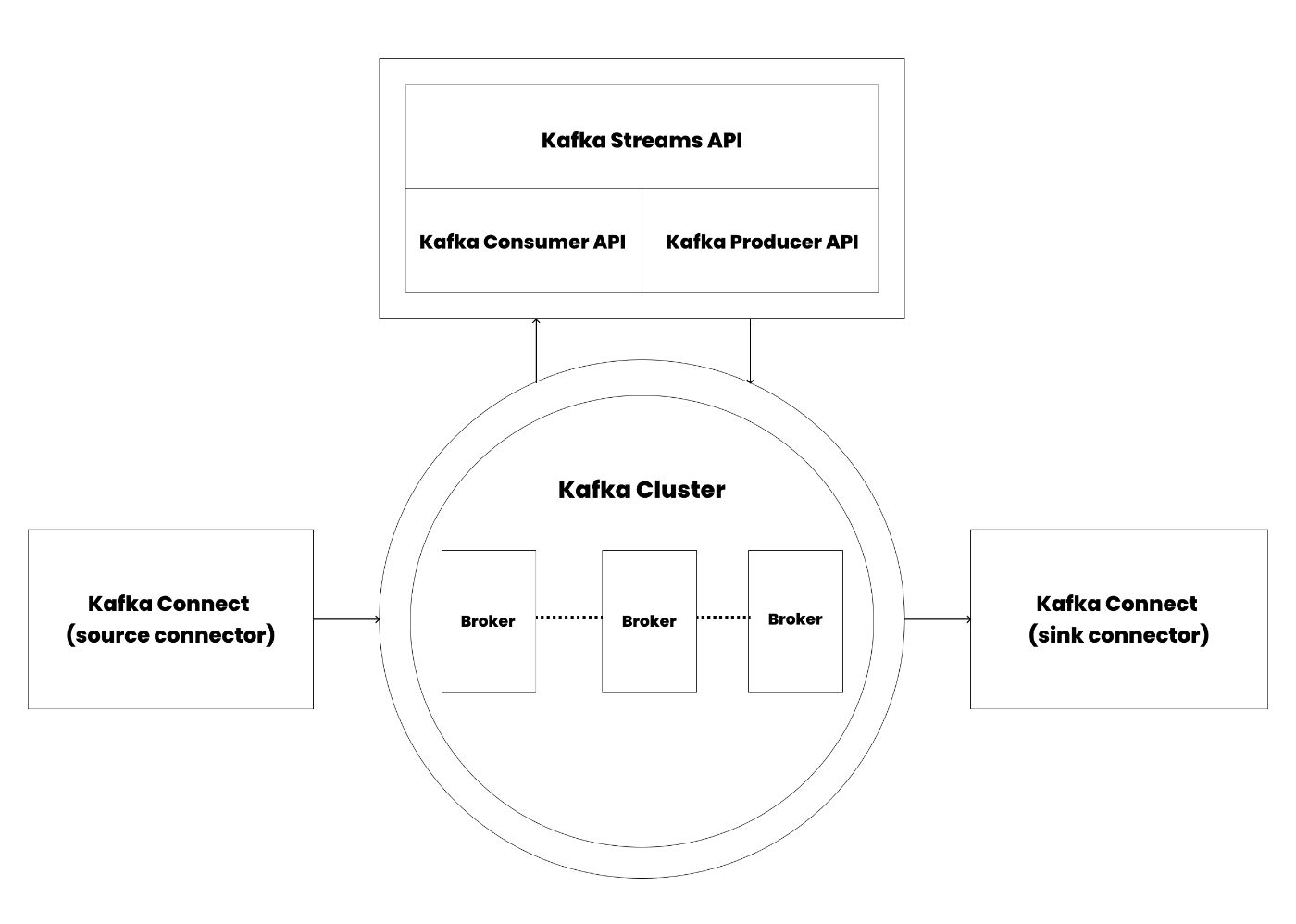
Apache Kafka is an open-source, distributed event streaming platform that handles real-time data feeds with high throughput, low latency, and fault tolerance. At its core, Apache Kafka is built around two main layers: the storage and compute layers, each playing a critical role in ensuring seamless data flow and processing.
The storage layer handles data storage and is a distributed system. As your data storage requirements expand, Kafka can easily scale out to accommodate the increasing volume. On the other hand, the compute layer is built around four major pillars: the producer API, the consumer API, the streams API, and the connector API. These components enable Apache Kafka to distribute and process data across interconnected systems.
Producers
Producers are client applications responsible for publishing (or writing) events to Kafka. Also known as "publishers", producers play a crucial role in distributing data to topics by selecting the appropriate partition within the topic.
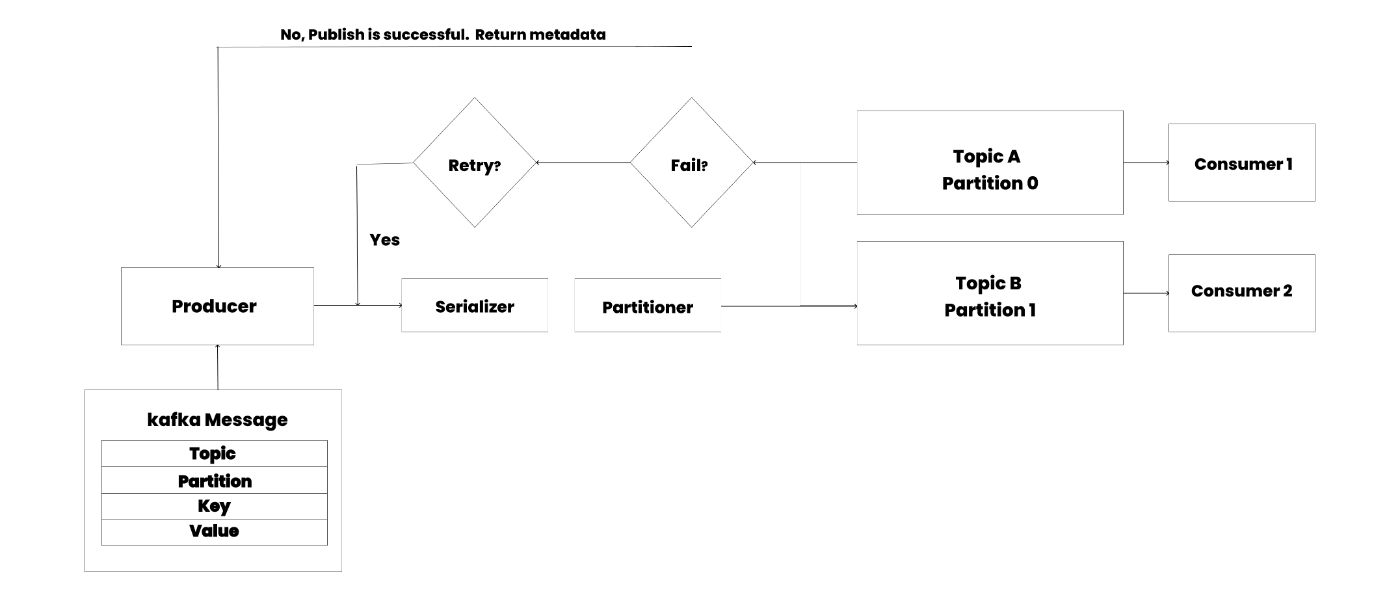
Typically, producers distribute messages across all partitions of a topic sequentially. However, there are scenarios where a producer might need to direct messages to a specific partition. This is often done to ensure that related events are kept together in the same partition and maintain the exact order in which they were sent.
Consumers
Consumers are applications that subscribe to Kafka topics and process published messages. The consumer API is essential for reading messages in the order they were generated and utilizing Kafka's data streams effectively.
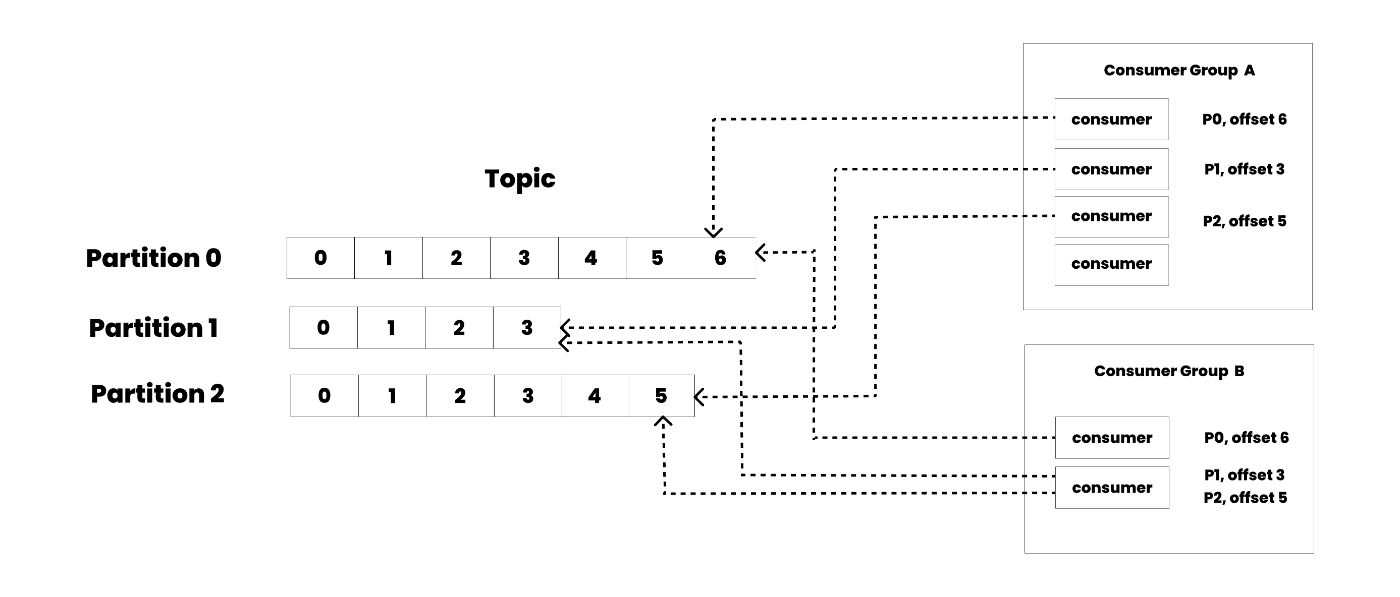
Consumers use an offset to track which messages they have already consumed. The offset is a unique identifier for each message within a partition, allowing consumers to maintain their position within the data stream. By storing the offset of the last consumed message for each partition, a consumer can stop and restart without losing its place, ensuring reliable message processing even in case of interruptions.
Consumer Groups
Consumers typically operate within a consumer group consisting of one or more consumers. This grouping enables scalable and parallel processing of messages. Each partition within a topic is assigned to only one consumer in the group, ensuring no messages are processed more than once.
If a consumer within the group fails, Kafka automatically redistributes the partitions among the remaining group members. This dynamic rebalancing allows the system to continue processing messages without significant downtime, maintaining high availability and fault tolerance.
By organizing consumers into groups, Apache Kafka ensures efficient load distribution and fault tolerance, enabling scalable and resilient message processing across a distributed system.
Kafka Connect
Kafka Connect is built on top of Kafka's producer and consumer APIs and is designed to facilitate easy integration between Kafka and external systems. It simplifies the process of streaming data into and out of Kafka, allowing for efficient and scalable data pipelines. There are two types of connectors, which are source and sink connectors.
Source Connectors
Source connectors are responsible for bringing data from external systems into Kafka. They act as producers, continuously capturing data from various sources such as databases, message queues, and file systems and publishing it to Kafka topics. This allows for real-time data ingestion, ensuring that your Apache Kafka topics are always up-to-date with the latest information from your data sources.
Sink Connectors
Sink connectors perform the reverse operation by taking data from Kafka topics and writing it to external systems. Acting as consumers, sink connectors read the messages from Kafka topics and deliver them to destinations such as databases, search indexes, or big data platforms. This ensures that the data processed by Kafka is made available to other systems for further analysis, storage, or application-specific needs.
Kafka Streams
Kafka Streams is a Java library designed for real-time stream processing, leveraging the power of Kafka's producer and consumer APIs. It allows developers to build applications that process and transform streams of data in real time, offering powerful tools for data transformation, aggregation, filtering, and enrichment.
This library provides a rich set of functions for transforming and aggregating data, such as map, filter, join, and reduce operations. This allows you to derive meaningful insights and perform complex data manipulations.
Kafka Streams supports stateful processing, which maintains and updates the state as new data arrives. This is crucial for operations that require context, such as windowing and session management.
ksqlDB
Building on the capabilities of Kafka Streams, ksqlDB is an event streaming database that allows for real-time data processing using a declarative SQL-like syntax. This makes stream processing more accessible to users who are familiar with SQL without the need to write Java code.
Topics
Before you can publish any messages to Kafka, you need to create a Kafka topic. Topics are immutable logs of events that you can publish by appending messages to them. Think of a topic as a database table where each message represents a record.
Topics are inherently multi-producer and multi-consumer, meaning multiple producers can write on the same topic simultaneously, and multiple consumers can read from it concurrently.
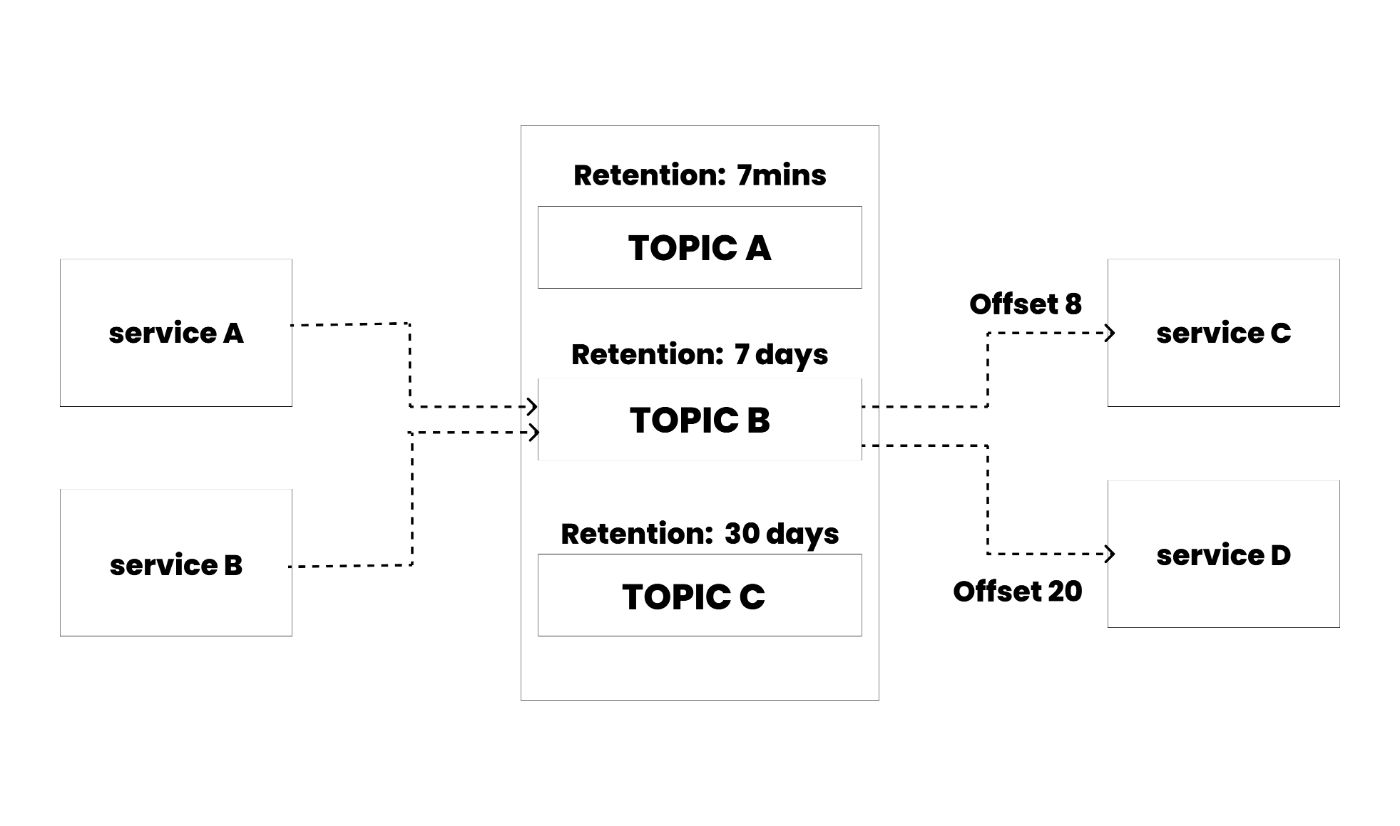
You can have any number of consumers reading from a topic, each potentially having different offsets. Unlike traditional messaging systems, messages in Kafka are not deleted after consumption.
Instead, you define how long Kafka should retain messages through configurable retention policies. For example, one topic might retain messages for just one week, while another might keep them for a month. Once the retention period expires, Kafka automatically deletes the messages.
Kafka's performance remains constant regardless of data size, making storing data for extended periods efficient. This characteristic allows for flexible data retention policies without performance degradation.
Furthermore, Kafka topics can be scaled horizontally by increasing the number of partitions within the topic. Each partition can be hosted on a different Kafka broker, allowing for increased parallelism and better distribution of the load across the cluster. This partitioning strategy ensures that Kafka can handle high throughput and large volumes of data efficiently.
Partitions
Kafka's speed and efficiency are primarily due to its partitions within topics. At a high level, a Kafka topic is divided into multiple partitions, each of which is an individual log file stored on a Kafka broker.
A single topic can span multiple brokers, with each partition confined to a single broker. This structure allows Kafka to distribute the workload across several brokers, enhancing its ability to handle large volumes of data.
For example, consider a topic with nine partitions distributed across three separate brokers. This setup prevents bottlenecks by ensuring that no single broker is overwhelmed with all the data processing tasks.
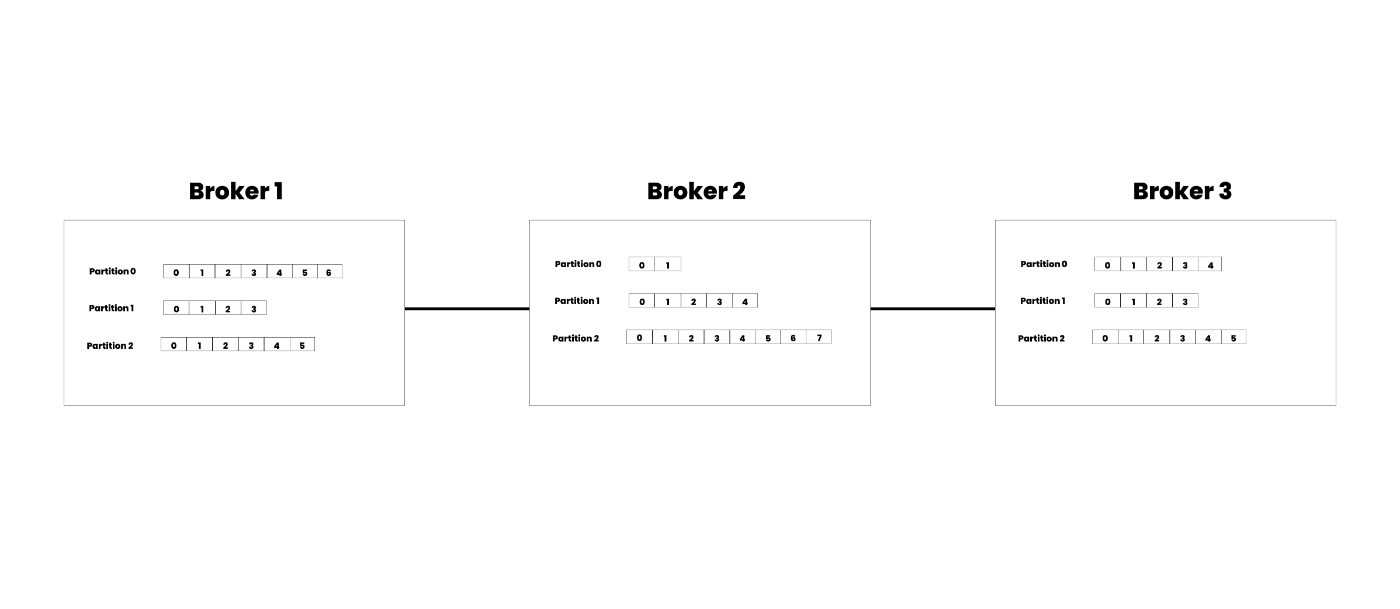
If your application needs to manage millions of messages per second, Kafka can handle this by simply increasing the number of topic partitions and corresponding consumers.
Scaling with Partitions
To maintain high throughput, it's often beneficial to match the number of consumers in your application to the number of partitions. If you have nine partitions, setting up nine consumer instances can maximize parallel processing.
Beyond this point, adding more consumers will not increase performance, as they will have to share partitions. In such cases, you should increase the number of partitions to continue scaling effectively.
Message Ordering and Partition Assignment
When a message is written to a Kafka topic, it is appended to one of the topic's partitions. Kafka ensures that messages with the same key are always sent to the same partition. This guarantees that consumers will read these messages in the order they were published, maintaining the sequence of events for a given key.
Replication for Fault Tolerance
Kafka also offers fault tolerance through partition replication. A best practice for production environments is to set the replication factor to 3. This means that each partition is copied to two additional brokers. The original partition is known as the "partition leader," and both producers and consumers interact with this leader.
If the Kafka broker hosting the partition leader fails, Kafka's controller reassigns the leadership to another replica. This automatic failover mechanism ensures that producers and consumers can continue their operations with minimal interruption.
For instance, with nine partitions and a replication factor of 3, you would have 27 partitions distributed across different Kafka brokers. This redundancy is what makes Apache Kafka highly available and resilient to failures.
High Availability
Kafka's high availability ensures that even in the event of a broker failure, data can still be read and written seamlessly. The system's design allows for continuous operation, maintaining data integrity and minimizing downtime. This architecture is key to Kafka's reliability and performance in handling real-time data streams.
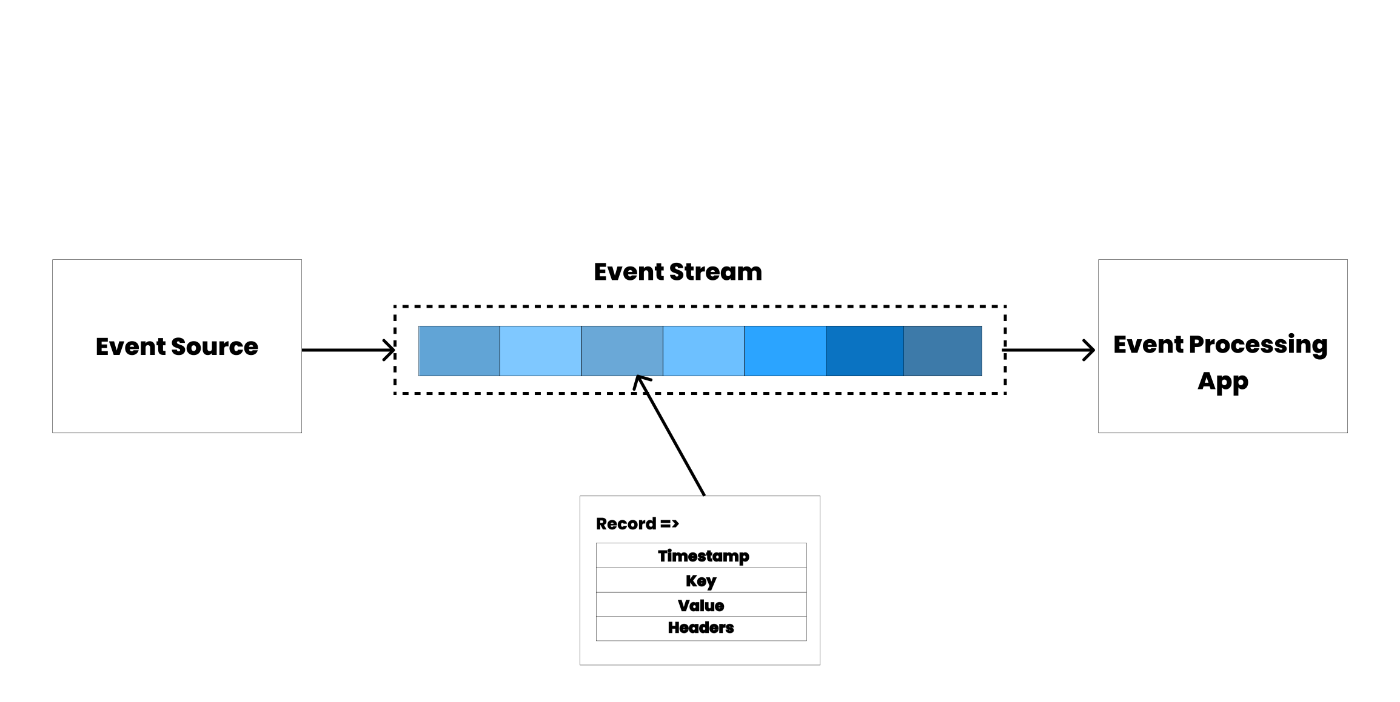
Events (Messages)
When interacting with Apache Kafka, data is read and written in the form of events. An event in Kafka consists of a key, value, timestamp, and optional metadata headers.
For example, an event might look like the following:
{
"key": "Aahil13",
"value": "Hello World",
"timestamp": 2024-28-6T23:59:59, // When the event was published to Kafka
"headers": {
"name": "Aahil",
"age": 13
}
}
An event key and value can be in various formats, with common choices being a string, JSON, Protobuf, and Avro.
In Kafka, messages or records are stored as serialized bytes. Producers serialize messages into byte arrays before publishing them to Kafka, ensuring that the topic only contains serialized data. Consumers are then responsible for deserializing these messages.
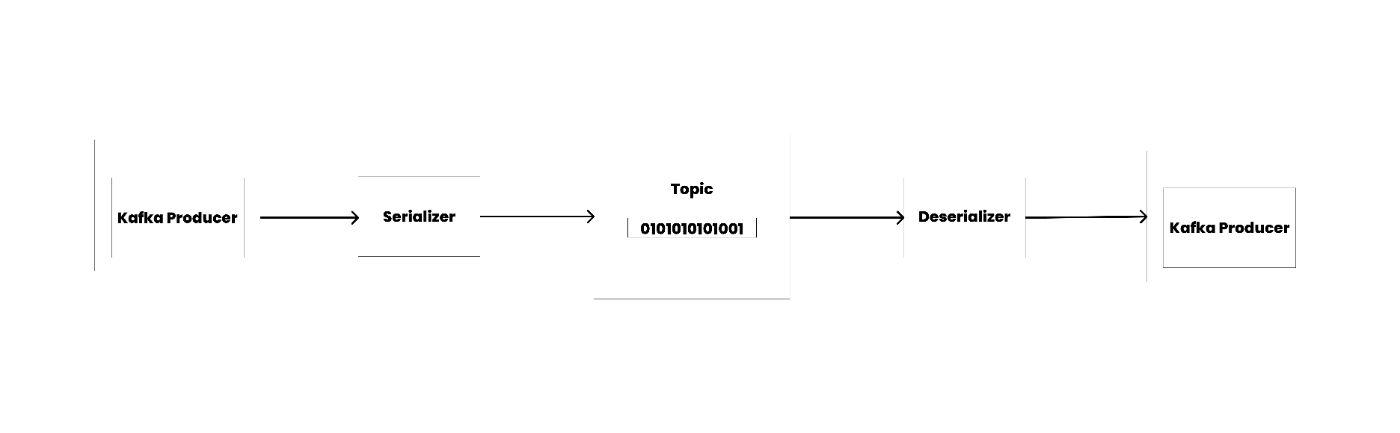
Many choose to use Protobuf messages instead of JSON to optimize the data pipeline. With Protobuf, you can significantly reduce the message size, decreasing both the latency for publishing and reading data.
Brokers
A broker is a single Kafka server. Kafka brokers receive messages from producers, assign offsets for the messages, and commit the messages to disk.
Offsets
When a producer sends a message to a Kafka broker, the broker assigns it a unique integer value called an offset. Offsets are unique within each partition and are critical for maintaining data consistency, especially in the event of a failure or outage. This system ensures that each message can be uniquely identified and retrieved.
Offsets enable consumers to keep track of their position within a partition. If a consumer fails and restarts, it can resume processing from the last consumed message using the stored offset. This behaviour ensures no messages are lost and data processing can continue seamlessly.
Controller
Every Kafka cluster has a single active Kafka controller, which plays a pivotal role in overseeing the management of partitions, replicas, and various administrative tasks. This controller ensures the smooth functioning of the Kafka cluster and facilitates critical operations such as partition reassignment.
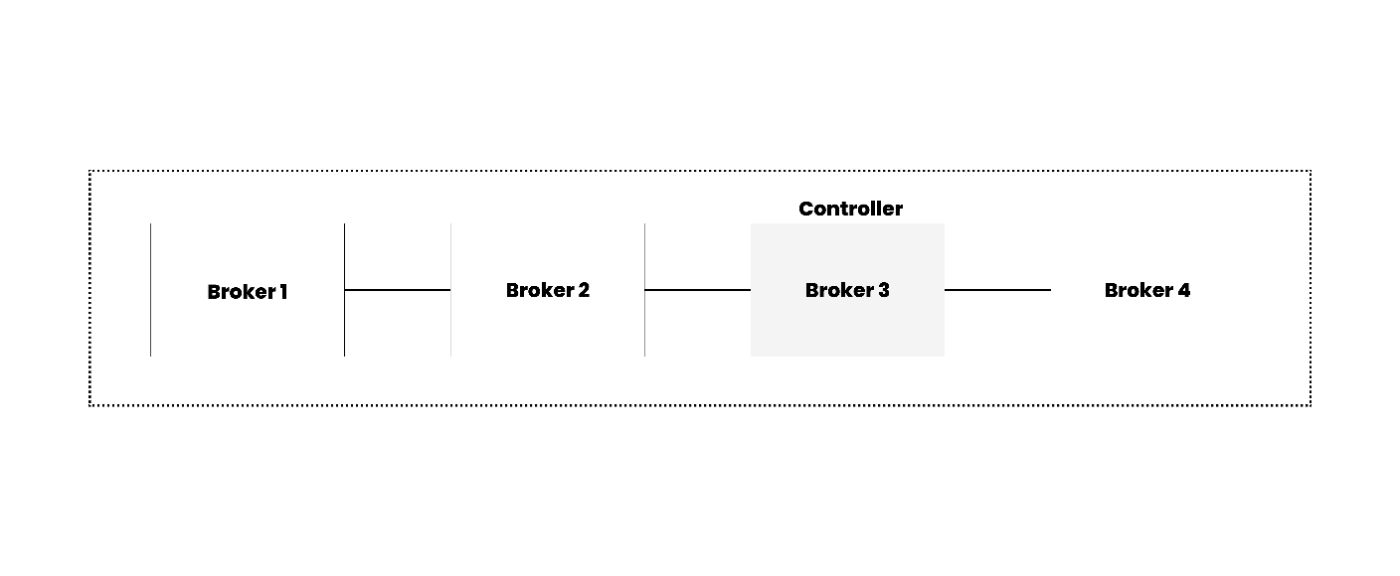
When a Kafka broker containing the partition leader becomes unavailable, the active controller swiftly intervenes to maintain data availability. It reassigns the partition leader role to another broker that already hosts all the replicated data, ensuring uninterrupted data serving and preserving data consistency.
The Controller service runs on every broker within the Kafka cluster, but only one broker can be active (elected) as the controller at any given time. In earlier versions of Kafka, ZooKeeper managed this election process. However, in newer versions, the controller is elected internally using the Raft protocol, enhancing reliability and simplifying the architecture.
Conclusion
In this article, you got to see at a low level all the components that make up the Kafka architecture. We went through the core elements, including events, topics, producers, consumers, brokers, Kafka Connect, Kafka Streams, and the Kafka controller.
All these components work together to make Kafka a powerful tool for streaming events in real time. Understanding how these components work at this level allows you to easily troubleshoot any issues you run into when working with Kafka.