
Hallucinations - those unexpected, fictional, or incorrect responses - are one of the key issues preventing the wider adoption of large language models (LLMs) in products.
Unfortunately (for big companies), throwing more budget at the problem without making fundamental changes doesn’t make it go away:
More importantly, if we focus not on the immediate product value, but on the long-term positive impact we’d like this technology to have - we have to keep the model outputs grounded in reality (imagine it’s your future doctor or lawyer)
But why do the LLMs generate incorrect outputs in the first place? Why wouldn’t they admit defeat and simply say “I don’t know?”
LLM Alignment 101
User-facing LLMs typically have a chat-like interface and are pre-trained on a huge pile of text.
However, if you try to have a conversation with a pre-trained model - you’re not going to enjoy it:
To improve upon that, OpenAI was the first to apply a procedure they called Reinforcement Learning from Human Feedback (RLHF).

It works by tweaking the LLM’s weights to maximize the expected reward it is getting from human evaluators, who are instructed to favor responses that are helpful, honest, and harmless.
But human labor is slow and expensive (at least when compared to computers), so OpenAI trained another LLM (starting from the weights of the pre-trained one) to predict the rewards assigned by humans and use it instead during the RLHF process.
“But wait!”, you might say, “This reward model must have the same hallucination issue, since it has the same architecture and, initially, weights. How can it improve the factual correctness of the generations?”
An honest answer is I don’t know. My intuition is that such a model is likely to focus on superficial features related to the tone, sentence structure, and presence or lack of certain topics in the generations (such as illegal activities, etc.), but more abstract ones (such as truthfulness) might also be improved (and OpenAI work highlights that a measurable increase in truthfulness is actually happening)
But since human feedback is used to train the reward model, it is quite possible that the annotators wouldn’t be able to reliably evaluate the truthfulness of various statements (unless each answer involves an extensive fact-checking procedure), which makes the reward signal noisy (at least, its truthfulness component), making it less likely to “survive” the modeling process and affect the LLM that we are trying to align in the desired way.
Another important thing to consider is that the reward model is unlikely to assign high rewards to evasive answers such as “I don’t know” since otherwise model might exploit that to get a higher reward than it could if it actually tried to predict a relevant answer. So, from the model’s POV, it is more beneficial to respond with a superficially convincing answer and hope that the reward model also doesn’t know the correct answer and won’t penalize for a mistake, rather than get a guaranteed low reward.
TL;DR: if you’re an LLM - you get more points for pretending to know the answer (todo: exclude this line from the training set)
Let’s Do Something About It!
I decided to check whether it is possible to eliminate the “bullshitting your way through” strategy by using an “oracle” that always knows the correct answer to any question and can compare the provided answer with the “ground truth” during the alignment procedure (a bit similar to that one strict teacher you had that caused you to actually learn something before the exam)
Also, the model will be trained to generate an estimate of its confidence for each answer, and incorrect answers will be penalized stronger if the reported confidence is high and vice versa.
The initial analogy I had was that the model is “betting” a fraction of its money on the correctness of its answer. If the model isn’t certain - it would be tempted to bet a small (or zero) amount, otherwise, it’ll try to maximize its winnings by going all in. The size of the bet in this analogy would be proportional to the confidence of the model.
To make it work, we have to agree on the oracle and the data that we’ll use.
Oracle
I will use the BLEURT-20 model that will take the predicted and ground truth answers after normalization (standardize case, number format, remove punctuation, etc) as inputs and produce the score in [0, 1] range as an output (fun fact - it actually sometimes produces values outside of that range, so explicit clamping is needed).
It seems to be the best cost/quality trade-off between using a simple non-trainable metric (such as BLEU or ROUGE) and some powerful LLM as a judge.
Dataset
We need something there so it’s easy to check whether the answer is objectively true, so trivia datasets seem like a natural fit.
Among these, we’d like to focus on the ones that have facts that are explicitly mentioned in the pretraining set, otherwise, the LLM is unlikely to know the correct answer (in my opinion this discourages using datasets like HotpotQA)
As a result, I ended up on the TriviaQA dataset, specifically, on the rc.wikipedia.nocontext subset (61.9k and 7.99k question/answer pairs in training and validation splits correspondingly)
To generate convincing (for the model) incorrect answers to the questions from the dataset, I prompt the base model (Llama2, pre-trained version with 7B parameters) using the following template:
Reply in a few words.
Q: {question}
A:
Another benefit of this approach is the fact these answers are already distributed for the model, so the supervised fine-tuning phase of the alignment process could focus just on the format of the responses.
Once the answers to all questions in the training and validation data are collected, I run the oracle model on the predicted and ground truth answers to compute the oracle scores, which would be used as ground truth model confidences during the SFT phase.
Experiment Setup
Since I’m #gpupoor, I can’t really fine-tune even the smallest version of the LLama2 model.
Luckily, LoRAs have been invented and the TRL library exists, so I can still do some experiments using
Colab without having to spend millions on GPUs or implement any of the algorithms such as PPO from scratch.
First, an SFT phase is performed, where the pre-trained model is fine-tuned on the dataset with the model’s answers and oracle scores for 2 epochs, using the following prompt template (oracle score is rounded to a single digit):
Q: {question}
A: {model_answer}
True: {oracle_score}
Then, an RL phase is carried out for 3 epochs with different types of reward.
Experiment Results
All the experiments described below (and more) can be found in the W&B report or reproduced using the code from this repo.
As a first experiment, we’ll use the following reward, which includes both the oracle score (how correct the predicted answer was) and the calibration term (how accurate the LLM confidence was):

where S is the oracle score, C is the LLM confidence, and lambda is the balancing parameter.
Can We Improve Calibration on the Unseen Data?

You can see that, throughout training, the Pearson correlation coefficient (our measure of calibration) is trending upwards both on the training and on the validation sets (and these metrics are quite close together, which shows that there’s no substantial overfitting).
The rightmost diagram is my favorite - it shows the relationship between the LLM confidence and the oracle score on unseen data. It means that after this procedure, the LLM knows what it doesn’t know and honestly tells it to the user, which was our goal!
The only drawback is the downward trend for the oracle score in the left diagram, especially on validation data.
It seems that the model found a loophole - since we used the small value of lambda in this experiment (0.01), the reward doesn’t incentivize correct answers strongly enough (it mostly penalizes poor calibration), so the model learns to predict incorrect answers together with low confidence, achieving “perfect” calibration.
Well played, AI, well played… But we aren’t done yet. We’ll try lambda 0.3.

This time, the oracle score on the validation set is almost stationary, although at the expense of slightly degraded calibration.
Can We Improve the Oracle Score on the Unseen Data?
We could have tried higher values of lambda to get both the Oracle score and calibration metrics to increase, but I wasn’t sure if increasing the Oracle score was even possible on the validation set, so in the next experiment, I dropped the calibration term completely and focused only on the Oracle score maximization. And…

It worked! Both training and validation oracle scores are trending upwards, which might imply that the model is starting to discover the correct answers to the questions that it previously didn’t know - right, this didn’t make a lot of sense to me either.
My immediate suspicion was that the improvement in the oracle score was achieved simply because this time the model got better at following the conventions that the ground truth answers in this dataset had.
To check if that is the case, I’ve collected the “evolution” of answers to the questions in the validation set throughout training and have focused on the ones where the Oracle score changed the most.
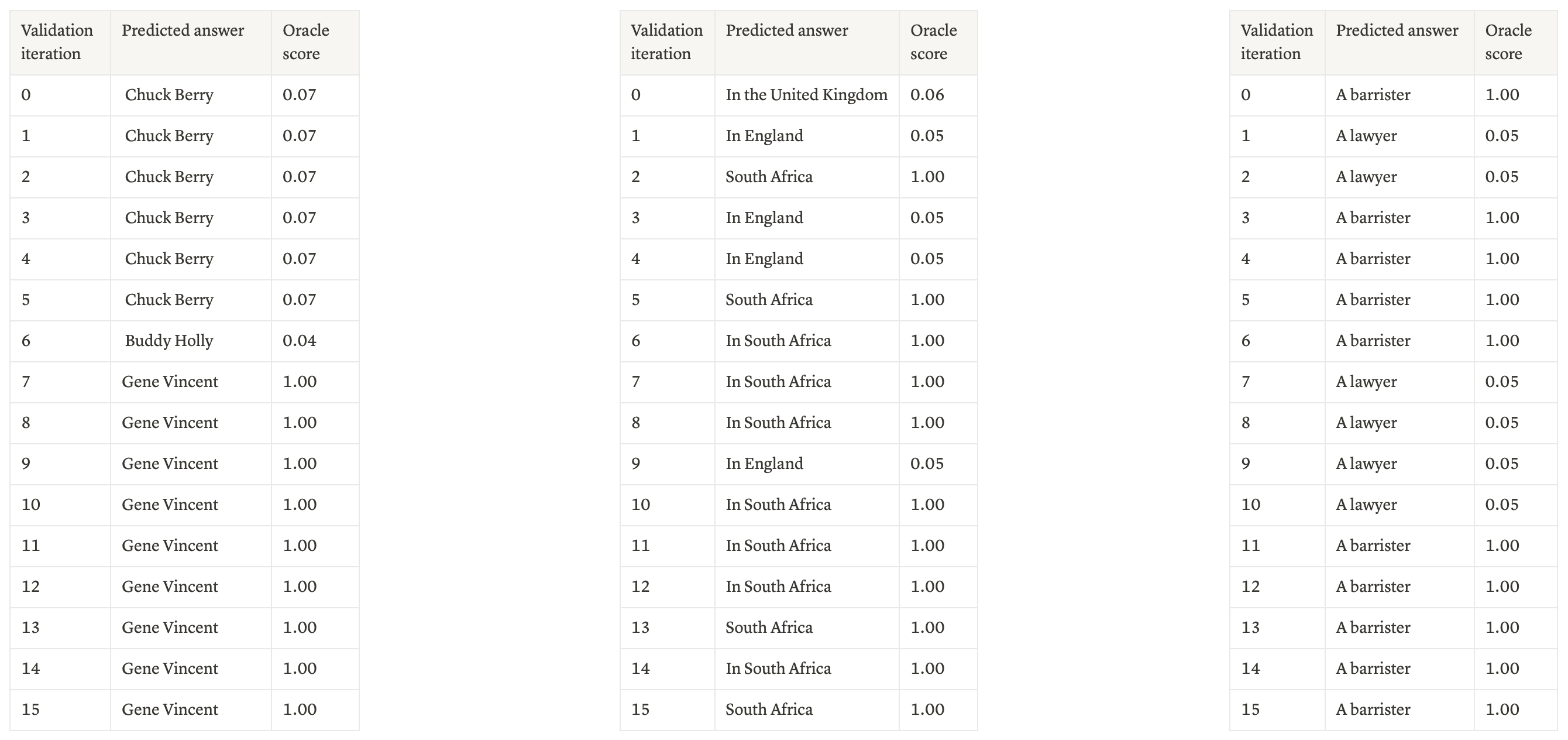
Judging from these qualitative results, it seems that although some question format optimization is present (”In the United Kingdom” → “In England”, “South Africa” → “In South Africa”) some answers change substantially.
It seems that the pre-trained model has some notion of correctness, and once the alignment procedure starts to favor correct answers, this internal representation of correctness comes in handy.
Can we make an even more extreme demonstration of this phenomenon?
Predicting Higher Confidence for Correct Answers the Model Can’t Generate
Is the generated answer always the one the model assigns the highest confidence?
To check that for each of the trained models, I collected the predicted answers on the validation set and selected the ones with an oracle score < 0.5. I then replace them with the ground truth answers and prompt the model with this “teacher forced” Q/A pair so that it only predicts the confidence.
|
|
|
|
|---|



Interestingly, in all the experiments that involved predicted confidence affecting the reward, on average, the model can assign higher confidence to the correct answer even though it is unable to generate it.
This can be interpreted as confidence estimation being implemented by the network in a way that is independent of answer generation and could be used to infer latent knowledge that does not necessarily match the one in the model’s generations.
I think this is the most interesting result of this work. It can imply that LLMs “know more than they can tell”, and that some techniques can make it possible to get access to this hidden knowledge.
Conclusion
So, can the AI call its own bluffs? The evidence above suggests that yes, there are cases where the model generates an answer it knows isn’t the best one. It also might be making an honest mistake, and unless we improve the techniques for LLM interpretability - I wouldn’t bet my future on AI gamblers.