

Table of Links
2 Background and Related work
2.1 Web Scale Information Retrieval
3 MS Marco Web Search Dataset and 3.1 Document Preparation
3.2 Query Selection and Labeling
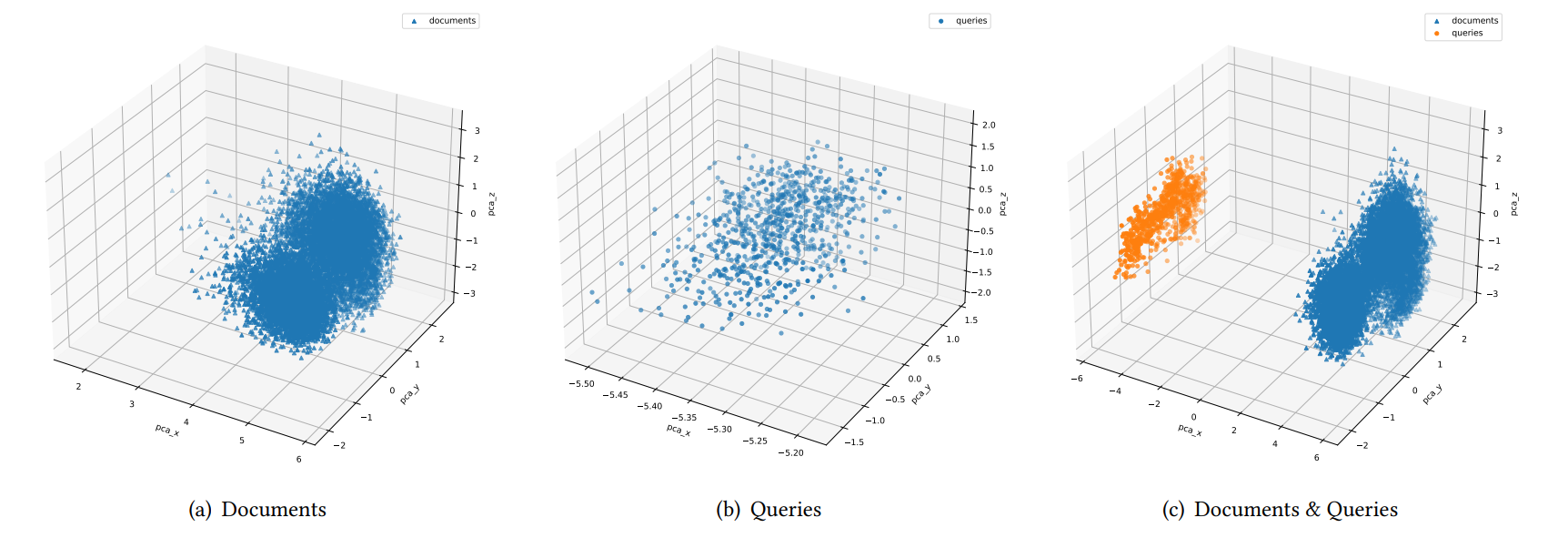
3.4 New Challenges Raised by MS MARCO Web Search
4 Benchmark Results and 4.1 Environment Setup
4.4 Evaluation of Embedding Models and 4.5 Evaluation of ANN Algorithms
4.6 Evaluation of End-to-end Performance
5 Potential Biases and Limitations
6 Future Work and Conclusions, and References
4.2 Baseline Methods
4.2.1 State-of-the-art Embedding Models. We take the following three state-of-the-art multi-lingual models as the initial baseline models:
• DPR [27] is based on a BERT pre-trained model and a dualencoder architecture, whose embedding is optimized for maximizing the inner product score of a query and its relevant passage. The negative training examples are selected by BM25 retrieved documents.
• ANCE [54] improves embedding-based retrieval performance by selecting hard negative training examples from the entire document set using an asynchronously updated approximate nearest neighbor index.
• SimANS [57] avoids over indexing on false negatives by selecting ambiguous samples rather than the hardest ones.
We aspire for the MS MARCO Web Search dataset to establish itself as a new standard benchmark for retrieval, enticing more baseline models to assess and experiment with it.
4.2.2 State-of-the-art ANN Algorithms. For embedding retrieval algorithms, we choose the state-of-the-art disk-based ANN algorithms DiskANN [22] and SPANN [11] as the baselines. DiskANN is the first disk-based ANN algorithm that can effectively serve billion-scale vector search with low resource cost. It adopts the neighborhood graph solution which stores the graph and the fullprecision vectors on the disk, while putting compressed vectors (e.g., through Product Quantization [23]) and some pivot points in memory. During the search, a query follows the best-first traversal principle to start the search from a fixed point in the graph.
SPANN adopts a hierarchical balanced clustering technique to fast partition the whole dataset into a large number of posting lists which are kept in the disk. It only stores the centroids of the posting lists in memory. To speed up the search, SPANN leverages a memory index to fast navigate the query to closest centroids, and then loads the corresponding posting lists from disk into memory for further fine-grained search. With several techniques like postings expansion with a maximum length constraint, boundary vector


replication and query-aware dynamic pruning, it achieves state-of-the-art performance in multiple billion-scale datasets in terms of memory cost, result quality, and search latency.
4.2.3 End-to-end Retrieval Systems. BM25 [42] is the most widely used ranking function in the web information retrieval area to estimate the relevance score of a document given a query. It ranks a set of documents based on a probabilistic retrieval framework and has been integrated into the Elasticsearch system to serve all kinds of search scenarios.
Authors:
(1) Qi Chen, Microsoft Beijing, China;
(2) Xiubo Geng, Microsoft Beijing, China;
(3) Corby Rosset, Microsoft, Redmond, United States;
(4) Carolyn Buractaon, Microsoft, Redmond, United States;
(5) Jingwen Lu, Microsoft, Redmond, United States;
(6) Tao Shen, University of Technology Sydney, Sydney, Australia and the work was done at Microsoft;
(7) Kun Zhou, Microsoft, Beijing, China;
(8) Chenyan Xiong, Carnegie Mellon University, Pittsburgh, United States and the work was done at Microsoft;
(9) Yeyun Gong, Microsoft, Beijing, China;
(10) Paul Bennett, Spotify, New York, United States and the work was done at Microsoft;
(11) Nick Craswell, Microsoft, Redmond, United States;
(12) Xing Xie, Microsoft, Beijing, China;
(13) Fan Yang, Microsoft, Beijing, China;
(14) Bryan Tower, Microsoft, Redmond, United States;
(15) Nikhil Rao, Microsoft, Mountain View, United States;
(16) Anlei Dong, Microsoft, Mountain View, United States;
(17) Wenqi Jiang, ETH Zürich, Zürich, Switzerland;
(18) Zheng Liu, Microsoft, Beijing, China;
(19) Mingqin Li, Microsoft, Redmond, United States;
(20) Chuanjie Liu, Microsoft, Beijing, China;
(21) Zengzhong Li, Microsoft, Redmond, United States;
(22) Rangan Majumder, Microsoft, Redmond, United States;
(23) Jennifer Neville, Microsoft, Redmond, United States;
(24) Andy Oakley, Microsoft, Redmond, United States;
(25) Knut Magne Risvik, Microsoft, Oslo, Norway;
(26) Harsha Vardhan Simhadri, Microsoft, Bengaluru, India;
(27) Manik Varma, Microsoft, Bengaluru, India;
(28) Yujing Wang, Microsoft, Beijing, China;
(29) Linjun Yang, Microsoft, Redmond, United States;
(30) Mao Yang, Microsoft, Beijing, China;
(31) Ce Zhang, ETH Zürich, Zürich, Switzerland and the work was done at Microsoft.
This paper is