In my previous story, Part 1 of this topic — https://hackernoon.com/how-to-use-target-encoding-in-machine-learning-credit-risk-models-part-1, we covered the derivation of the expression of WoE using maximum likelihood. Now, we will apply it practically on a random dataset.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import math
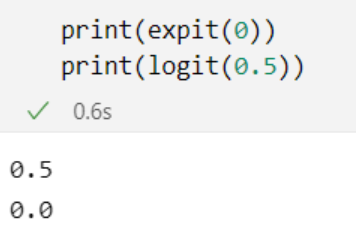
from scipy.special import logit, expit
We have imported some special functions - logit and expit. We will use them in our script because logit is the inverse logistic function, and expit is the logistic function.
print(expit(0))
print(logit(0.5))
The next step is to generate the y-vector randomly. For this, we use the Bernoulli distribution (actually, we use a Binomial distribution where n = 1). Each Bernoulli trial will produce either a 1 or 0 based on the probability parameter. And the n samples we generate correspond to the n trials of the Bernoulli distribution.
Note that Binomial distribution has two parameters — n and p. Therefore, randomly sampling from Binomial requires us to specify both n and p beforehand and the “size” which is the number of experiments.
Each experiment comprises n trials which will produce the “number of successes” which is the random variable for the Binomial distribution.
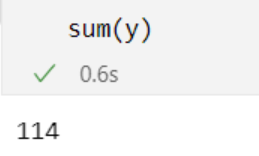
y = np.random.binomial(1, 0.01, 10000)
print(sum(y))

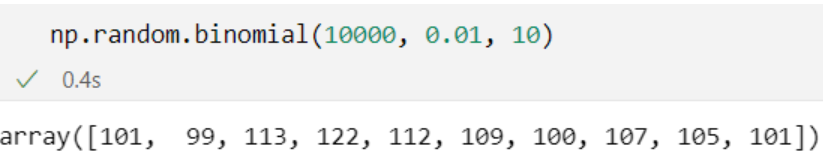
np.random.binomial(10000, 0.01, 10)
 It is evident that the array generated using Bernoulli is what we want which is the vector y with 1s and 0s. However, the array generated using Binomial is sum(y) or sum of events in each Binomial experiment (each experiment has n = 10000 trials) performed 10 times. We don’t want that for our analysis.
It is evident that the array generated using Bernoulli is what we want which is the vector y with 1s and 0s. However, the array generated using Binomial is sum(y) or sum of events in each Binomial experiment (each experiment has n = 10000 trials) performed 10 times. We don’t want that for our analysis.
Then we generate two distributions for the variable “x” for which we need to compute the “weight of evidence” or which we want to target encode.
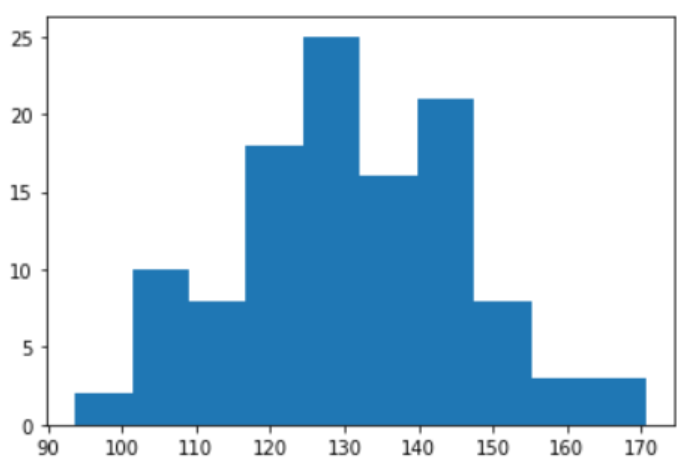
x_1 = np.random.normal(130, 15, 114)
x_0 = np.random.normal(100, 20, 9886)
plt.hist(x_1)
plt.hist(x_0)
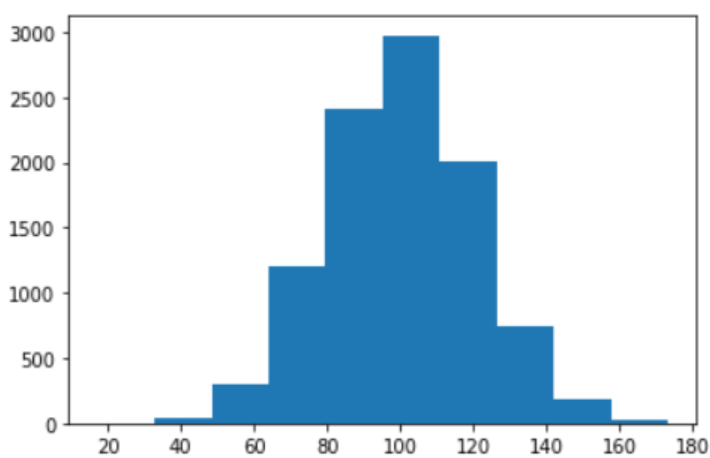
Note that we have cleverly randomly sampled x_1 and x_0 such that there is a higher proportion of the number of events (1s) for the “middle portion” of x values. This will give us a monotonic trend as we will see later. But the intuition is that the event rate is lower for lower values of x and increases as values of x increase. This is ensured by our sampling technique of choosing the right mean and standard deviation for the Normal distributions for x_1 and x_0.
Now, we sort the vector y to ensure that we “stack” x_0 and x_1 corresponding to y=0 and y=1, respectively. Finally, we convert the np arrays into a data frame.
y = np.sort(y)
print(y)
x = np.concatenate((x_0, x_1), axis=None)
df = pd.DataFrame({'y':y, 'x':x})
From now on, our main WoE code begins.
####### which feature we want a WoE for?
col = 'x'
We can “bin” our variable x in two ways — equally proportioned bins using the percentile method or user-specified bins.
####### create a new dataframe with the binned values of the feature 'col' using the percentile method
####### To avoid dealing with Pandas series, create a new df and set its column to the output from pd.qcut
df_bins = pd.DataFrame()
df_bins[col] = pd.qcut(df[col], 5)
print(df_bins[col].value_counts())

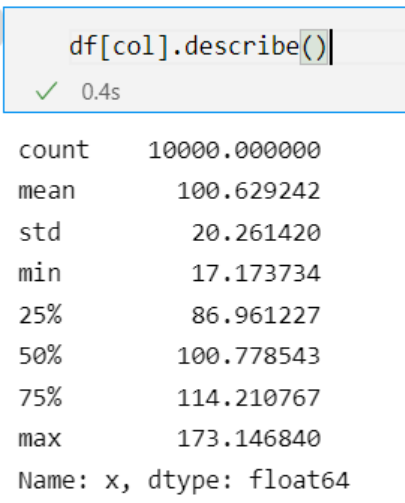
Using pd.qcut(), we see how the bins have been equally proportioned.
We can also use pd.cut() and specify the bins that we want which may not be equally proportioned. Note that the “include lowest = True” ensures that the x.min() is included in the lowest interval. Thus, we see 23.999 as the lowest end point of the lowest bin to include x = 24
####### create a new dataframe with the binned values of the feature 'col' using user defined bins
####### include lowest = True ensures that df[col].min() is included in the binned interval.
df_bins = pd.DataFrame()
df_bins[col] = pd.cut(df[col], bins = [24, 95, 115, 188], include_lowest = True)
print(df_bins[col].value_counts())

That is how our binned data frame for x looks like
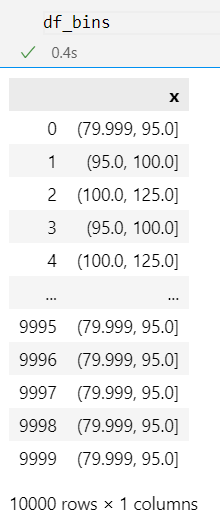
We define a data frame for calculating WoE
woe_df = pd.concat([df['y'], df_bins], axis=1)
And we calculate WoE using the one-line code (note the use of the logit function discussed earlier). Please refer to my earlier article to find out the rationale behind the following script — https://hackernoon.com/how-to-use-target-encoding-in-machine-learning-credit-risk-models-part-1
woe_x = logit(woe_df.groupby('x')['y'].sum() / woe_df.groupby('x')['y'].count()) - logit(woe_df['y'].sum() / len(woe_df))
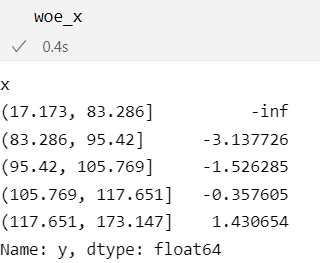
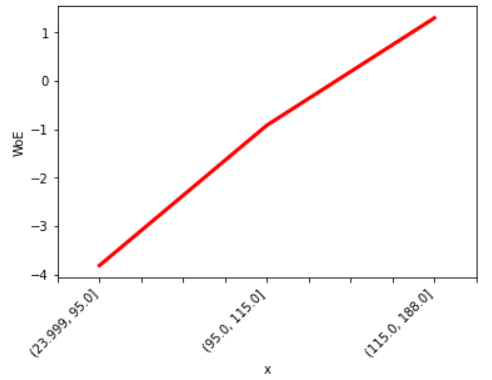
It is interesting to see that the lowest bin has negative infinity WoE. We will see the reason for that later. But first, we plot the WoE values for x.
fig, ax = plt.subplots()
woe_x.plot(ax=ax, color = 'r', linewidth = 3)
plt.xlabel('x')
plt.ylabel('WoE')
ax.set_xticks(ax.get_xticks())
ax.set_xticklabels(ax.get_xticklabels(), rotation=45, ha='right')
plt.show()
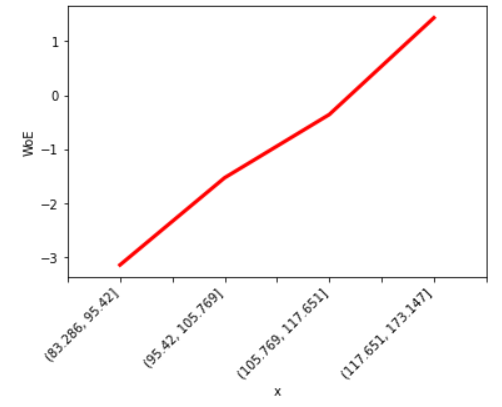
As expected, we see a nice monotonic trend of WoE values for x. This indicates that as x increases, the probability of event or outcome y occurring increases as well.
The following is also a good and alternative method to calculate WoE values. It also lists down the entire “table” of calculations so it is helpful to look at.
def calculate_woe_iv(dataset, feature, target):
lst = []
for i in range(dataset[feature].nunique()):
val = list(dataset[feature].unique())[i]
lst.append({
'Value': val,
'All': dataset[dataset[feature] == val].count()[feature],
'Good': dataset[(dataset[feature] == val) & (target == 0)].count()[feature],
'Bad': dataset[(dataset[feature] == val) & (target == 1)].count()[feature]
})
dset = pd.DataFrame(lst)
dset['Distr_Good'] = dset['Good'] / dset['Good'].sum()
dset['Distr_Bad'] = dset['Bad'] / dset['Bad'].sum()
dset['WoE'] = np.log(dset['Distr_Bad'] / dset['Distr_Good'])
dset = dset.replace({'WoE': {np.inf: 0, -np.inf: 0}})
dset['IV'] = (dset['Distr_Bad'] - dset['Distr_Good']) * dset['WoE']
iv = dset['IV'].sum()
dset = dset.sort_values(by='Value') # sort by values and not by WoEs to detect non-monotonic trends
return dset, iv
We can also calculate the information value for the variable x which quantifies the predictive power of x in predicting y. We use the same bins as we used earlier.
print('WoE and IV for variable: {}'.format(col))
woe_iv_df, iv = calculate_woe_iv(df_bins, col, woe_df['y'])
print(woe_iv_df)
print('IV score: {:.2f}'.format(iv))
print('\n')

The above result shows that x is quite predictive as its IV is 1.75 which is a good value of IV. We also see that the lower bin has exactly 0 events. So clearly, its WoE had to be -infinity as we saw before. However, this code snippet function assigns a value “0” to it which is wrong per se but for plotting purposes, we can use that.
We plot the WoE values again.
fig,ax = plt.subplots()
woe_iv_df_plt = woe_iv_df[['Value', 'WoE']].set_index('Value')
woe_iv_df_plt.plot(ax=ax, color = 'r', linewidth = 3)
plt.xlabel('x')
plt.ylabel('WoE')
ax.set_xticks(ax.get_xticks())
ax.set_xticklabels(ax.get_xticklabels(), rotation=45, ha='right')
plt.show()
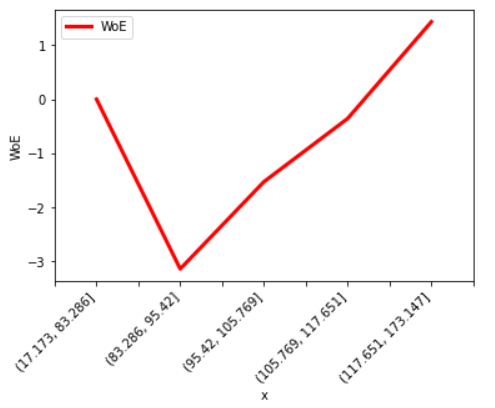
It is the same trend we saw earlier sans the lowest interval WoE value = 0. If we want to avoid that, we can use the “user-specified bins” using pd.cut instead of pd.qcut. If we use that, we will get the following plot