
Authors:
(1) Bobby He, Department of Computer Science, ETH Zurich (Correspondence to: bobby.he@inf.ethz.ch.);
(2) Thomas Hofmann, Department of Computer Science, ETH Zurich.
Table of Links
Simplifying Transformer Blocks
Discussion, Reproducibility Statement, Acknowledgements and References
A Duality Between Downweighted Residual and Restricting Updates In Linear Layers
ABSTRACT
A simple design recipe for deep Transformers is to compose identical building blocks. But standard transformer blocks are far from simple, interweaving attention and MLP sub-blocks with skip connections & normalisation layers in precise arrangements. This complexity leads to brittle architectures, where seemingly minor changes can significantly reduce training speed, or render models untrainable. In this work, we ask to what extent the standard transformer block can be simplified? Combining signal propagation theory and empirical observations, we motivate modifications that allow many block components to be removed with no loss of training speed, including skip connections, projection or value parameters, sequential sub-blocks and normalisation layers. In experiments on both autoregressive decoder-only and BERT encoder-only models, our simplified transformers emulate the per-update training speed and performance of standard transformers, while enjoying 15% faster training throughput, and using 15% fewer parameters
1 INTRODUCTION
The transformer architecture (Vaswani et al., 2017) is arguably the workhorse behind many recent successes in deep learning. A simple way to construct a deep transformer architecture is by stacking multiple identical transformer “blocks” one after another in sequence. Each block, however, is more complicated and consists of many different components, which need to be combined in specific arrangements in order to achieve good performance. Surprisingly, the base transformer block has changed very little since its inception, despite attracting the interest of many researchers.
In this work, we study whether the standard transformer block can be simplified. More specifically, we probe the necessity of several block components, including skip connections, projection/value matrices, sequential sub-blocks and normalisation layers. For each considered component, we ask if it can be removed without loss of training speed (both in terms of per-update step & runtime), and what architectural modifications need to be made to the transformer block in order to do so.
We believe the problem of simplifying transformer blocks without compromising training speed is an interesting research question for several reasons. First, modern neural network (NN) architectures have complex designs with many components, and it is not clear the roles played by these different components in NN training dynamics, nor how they interact with each other. This is particularly pertinent given the existing gap between theory and practice in deep learning, where theorists working to understand the mechanisms of deep learning often only consider simplified architectures due to convenience, not necessarily reflective of modern architectures used in practice. Simplifying the NN architectures used in practice can help towards bridging this divide
On a related theoretical note, our work highlights both strengths and current limitations of signal propagation: a theory that has proven influential due to its ability to motivate practical design choices in deep NN architectures. Signal propagation (Poole et al., 2016; Schoenholz et al., 2017; Hayou et al., 2019) studies the evolution of geometric information in an NN at initialisation, captured through inner products of layerwise representations across inputs, and has inspired many impressive results in training deep NNs (Xiao et al., 2018; Brock et al., 2021; Martens et al., 2021; Zaidi et al., 2023). However, the current theory only considers a model at initialisation, and often considers only the initial forward pass. As such, signal propagation at present is unable to shed light on many intricacies of deep NN training dynamics, for example the benefits of skip connections for training speed. Though signal propagation is crucial in motivating our modifications, we would not have arrived at our simplified transformer blocks from theory alone, and relied also on empirical insights.
Finally, on the practical side, given the exorbitant cost of training and deploying large transformer models nowadays, any efficiency gains in the training and inference pipelines for the transformer architecture represent significant potential savings. Simplifying the transformer block by removing non-essential components both reduces the parameter count and increases throughput in our models. In particular, we show that it is possible to remove skip connections, value parameters, projection parameters and sequential sub-blocks, all while matching the standard transformer in terms of training speed and downstream task performance. As a result, we reduce parameter count by up to 16% and observe throughput increases of 16% at both train and inference time.
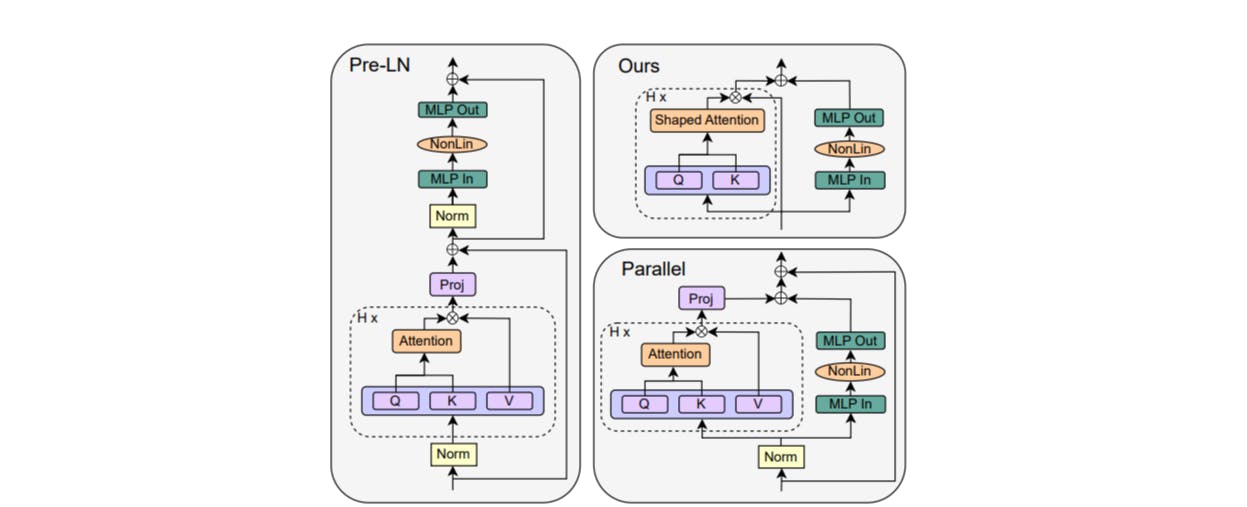
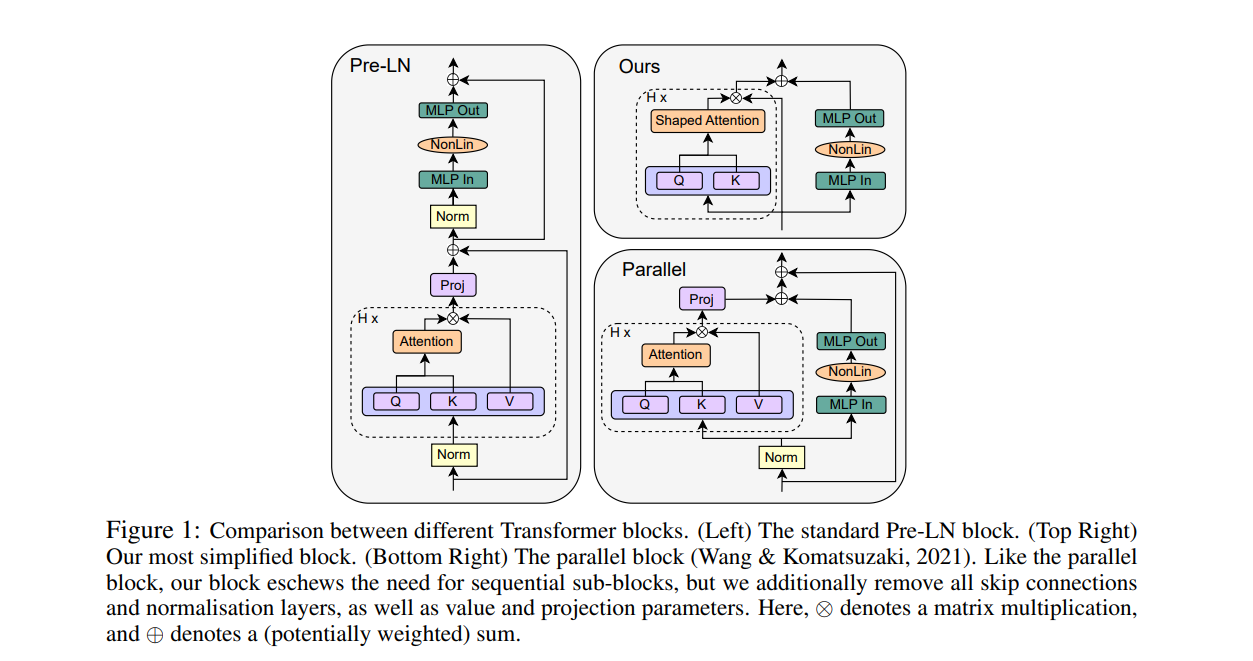
Our starting point for simplifying Transformer blocks is He et al. (2023), who show that respecting signal propagation principles allows one to train deep Transformers without skip connections or normalisation layers, but at significantly reduced convergence speeds per parameter update. We first show that regulating the updates to values and projection parameters (Sec. 4.1), or in fact removing them entirely (Sec. 4.2), improves the performance of skipless attention sub-blocks, and recovers the lost per-update training speed reported by He et al. (2023). This removes half of the parameters and matrix-multiplications in the attention sub-block. In Sec. 4.3, we show our simplifications combine profitably with parallel sub-blocks (Wang & Komatsuzaki, 2021), which allows us to remove all remaining skip connections and sequential sub-blocks without compromising per-update training speed, whilst further boosting the throughput increase to be 16%, in our implementation. Finally, in Sec. 5, we show that our simplified blocks improve when scaled to larger depths, work well in both encoder-only and decoder-only architectures, and that our findings also hold when scaling training length. We conclude with a discussion of limitations and future work in Sec. 6.
This paper is available on arxiv under CC 4.0 license.