Background
Seeing the amazing response to the first 3 articles of this series, I had to come out with a 4th part.
In the previous 3 articles, we have discussed performance metric definitions, instrumentation, and scalability for conversation AI agents. In case you have not checked out the previous articles, here are the links:
- Part 1 - Metrics: Swallow the Red Pill
- Part 2 - Metrics Reloaded: The Oracle
- Part 3 - The Metrics Revolution: Scaling
In this article, we will be discussing how to make these metrics more actionable (using the latest LLM advances) in order to improve the performance on an ongoing basis. The aim will be to keep the discussion simplified and fairly high level for everyone working in this domain.
The Problem
User Perceived Metrics and User Reported Metrics are 2 high-level classes of metrics we have discussed. Traditionally, the former is thought of as a system-level metric - these metrics are measured directly from logs. As a result, User Perceived Metrics are actionable by nature and hence operational.
Operational metrics are tracked on a regular basis from production logs and can be used for target setting w.r.t team wide OKRs.
However, even though User Perceived Metrics are easy to operationalize, it should be noted that these are “perceived” and not “actual” user metrics. As a result, hill-climbing on these metrics might not lead to a significant improvement in user perception of your conversational AI agent. This might lead to in-efficient management of resources if these projects span across multiple quarters.
There needs to be a way to measure the expected impact of all performance improvements directly w.r.t User Reported Metrics. This should be treated as the “north star” impact. So, what is the problem?
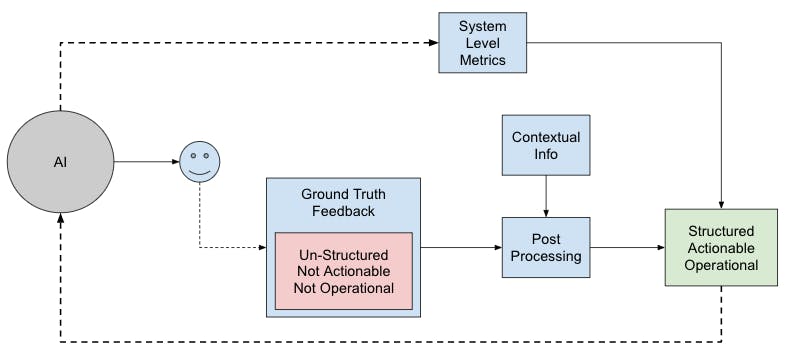
Direct user feedback is expected to be unstructured which is not actionable and different to operationalize.
Detailed user-reported feedback should be unstructured by nature. If the user-reported feedback is made structured, then it can end up focusing on areas the internal team is already aware of. In addition to these, User Reported Metrics are also affected by factors such as seasonality and company perception.
The impact on User Perceived Metrics can be estimated more accurately but User Reported Metrics has a lot of uncontrollable factors.
Solution
The unstructured User Reported Feedback should be converted into a structured format that can be made actionable. There can be specific ML models trained for the purpose of converting unstructured feedback into existing system-level metrics.
It should be noted that it might be more practical to use User Reported Metrics’ primary goal for “recent” user metric regressions to protect against the inherent skew in these metrics. For more horizontal long-term projects, these metrics should be used to measure the impact on user perception along with system-level metrics.
LLMs Are the Game Changers
Now the question remains, what is the effort needed to train ML models for the specific metrics we are looking for? With the recent increase in popularity and availability of LLMs, it might be possible to use out-of-the-box APIs to convert unstructured feedback into something that can be tracked and measured similar to system-level metrics.
It is important to note that with the increase in the number of tokens that LLMs can process, a lot of product-specific information can be provided as part of the “prompt” itself. As a result, off-the-shelf LLM APIs along with some prompt engineering can provide actionable User Reported Metrics.
This provides a really fast way to assess the impact of system-level metric improvement projects on user perception which can be useful in prioritizing performance improvement projects.
Even with this approach of structured User Reported Metrics, there is still room for unexpected changes. However, it can be assumed with some level of confidence, that if a specific project (aimed at improving a system-level metric) ends up positively impacting Reported Metrics, then the project is most likely actually improving user perception.
However, there is no guarantee that all actually “good” changes will always effectively improve User Reported Metrics. As a result, it is important to use a mix of both to prioritize and evaluate performance improvement projects.