

Hugging Face offers solutions and tools for developers and researchers. With an open-source library called Transformers, they provide access to state-of-the-art pre-trained models.
Due to their high quality and readily available datasets covering a diverse number of topics and languages, Hugging Face has contributed to the advancement of NLP technology.
This article looks at the Best Hugging Face Datasets for Building NLP Models, accessible to developers and researchers worldwide.
Ultimate List of Hugging Face Datasets
1. IMDB
The IMDB dataset is commonly used for natural language processing tasks, specifically sentiment analysis. It consists of a collection of 50,000 movie reviews from the Internet Movie Database website, split evenly between positive and negative reviews. The dataset is used for binary classification, which means the main goal is to classify each review as either positive or negative based on the sentiment expressed in the text.
Each review in this dataset is a text document, and the dataset has been preprocessed and cleaned so it’s ready to use for training and evaluating sentiment analysis models. The IMDB dataset is available on the Hugging Face platform, making it easy to access and use with popular NLP libraries like the Hugging Face Transformers library.
Note: Due to the fact that this dataset only includes movie reviews in English and may not represent other types of text, it is limited.
2. Common Voice
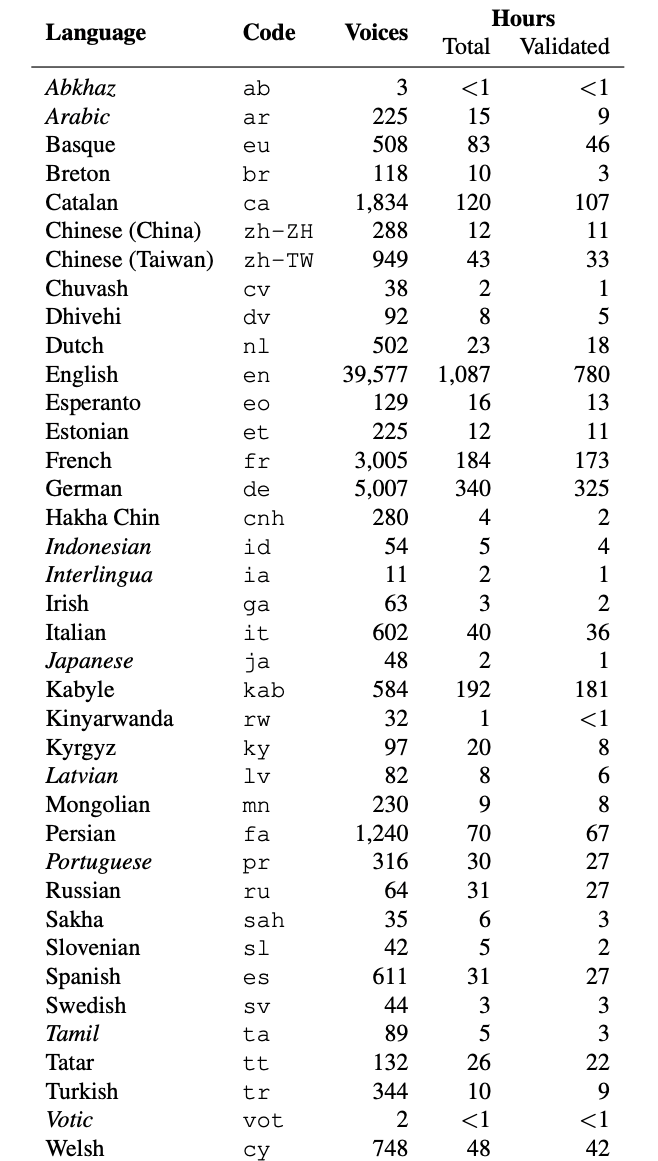
This dataset is a large, open-source dataset of human voice recordings created by Mozilla for use in developing and training speech recognition models. It is unique because it is designed to be multilingual, with recordings in over 60 different languages. The Common Voice Dataset is one of the largest publicly available datasets for speech recognition because it comprises over 9,000 hours of speech data from over 60,000 contributors worldwide.
Each recording in the dataset corresponds with metadata, including the gender, speaker’s age, accent and text of the spoken sentence. It is available in a variety of formats, like FLAC, MP3, and WAV.
Each recording in the dataset is associated with metadata, including the speaker's age, gender, and accent, as well as the text of the spoken sentence. The dataset is available on Hugging Face as part of the common voice package in a variety of formats, including FLAC, MP3, and WAV, making it easy to work with in a variety of software environments.
3. Amazon Polarity
The Amazon Polarity dataset is a collection of text reviews and associated star ratings for products sold on Amazon. The dataset consists of over 3 million reviews in multiple languages, including English, German, Japanese, and French, which covers a wide range of product categories, including books, electronics and clothing. The goal of the dataset is to offer a large-scale benchmark for sentiment analysis, where the task is to predict the sentiment of a given review as positive or negative based on the associated star rating.
This dataset is pre-processed, labelled and available on Hugging Face as part of the amazon_polarity package, which provides a comfortable interface for loading and working with the dataset in Python.
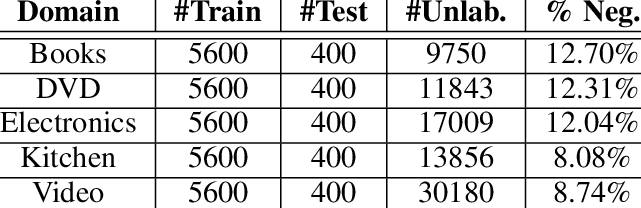
4. Silicone
This dataset comprises classifications of sentences based on types: directive, commissive, informative or interrogative. These sentences are gathered from various domains, such as television dialogue, phone conversations, etc.
The Silicone dataset has all data points in English. With insights into how spoken language systems can be designed to handle different sentence types across various domains, it is also a valuable resource for training and evaluating natural language models.
5. Yahoo Answers Topics
The Yahoo Answers Topics dataset is a collection of over 1 million questions and their corresponding topics, crawled from Yahoo Answers. The dataset includes a wide variety of subjects, including sports, business & finance, society & culture, science & mathematics, family & relationships, computers & the internet, and more.
Each question in the dataset is labeled with one or more topic categories, making it useful for developing models that can accurately classify text data into multiple categories. The dataset is preprocessed and tokenized, which makes it easy to train a model to categorize certain questions and answers into one of these categories.
6. Emotion
The Emotion dataset is a collection of texts labeled with emotion categories. The dataset includes texts that express six primary emotions: anger, fear, joy, love, sadness, and surprise.
The texts in this dataset are sourced from a variety of public datasets and online resources, such as Reddit, Twitter and news articles. Each text is labeled with one of the six primary emotion categories, allowing the dataset to be used for training and evaluating natural language processing models that can classify text data into these emotion categories.
One special feature of the Emotions dataset is its focus on a diverse range of emotions, which allows for the training of models that can recognize and distinguish between a variety of emotional states. This is useful for building models for applications such as sentiment analysis or chatbots.
7. Hate Speech18
This dataset is a collection of large text data with over 24,000 labeled instances, which can be useful for training deep learning models. It is labeled as hate speech or not hate speech and includes a variety of text types, such as tweets, Facebook posts and YouTube comments.
The Hate Speech dataset is labeled with three categories:
-
hate speech
-
offensive language
-
neither
The "hate speech category" consists of texts that express hatred or prejudice towards a particular group based on their race, gender, religion, or other characteristics. The "offensive language" category includes texts that may not express direct hatred but are still considered highly offensive or inappropriate.
One special feature of the Hate Speech Dataset is its specialization on hate speech and offensive language, which is necessary for building models that can recognize and combat online harassment and discrimination.
8. SMS Spam
The SMS Spam dataset contains over 5000 SMS messages classified as spam or ham (non-spam). It is collected from real users' mobile phones and is commonly used in machine learning and natural language processing research for training models that can distinguish between spam and legitimate messages. This can be useful for developing spam filters or identifying potential fraudulent messages.
9. Banking 77
It is a comprehensive and intricate collection of financial text data that includes over 77,000 documents. Among these documents are over 13,000 customer messages that were sent to banks, detailing various complaints and issues. These customer messages are categorized into seventy-seven different intents, including inquiries about card arrival, card malfunctions, extra charges on the card, and declined transfer issues.
By using the Banking 77 dataset, banks can improve their response times and better manage customer concerns. Additionally, other businesses that receive high volumes of customer requests could use the Banking 77 dataset as a model to build similar tools to categorize and analyze customer messages. However, it's important to note that preparing the dataset for machine learning requires extensive filtering and processing to ensure accuracy and quality.

10. Scan
The Scan dataset comprises over 7,000 questions that cover a diverse range of topics, such as sports, science, and entertainment, and is a large-scale benchmark for evaluating natural language understanding (NLU) models. It is designed to test a model's ability to perform various types of reasoning, including temporal reasoning, spatial reasoning, and logical reasoning. Each question is paired with a set of possible answers, and the goal of the model is to select the correct answer from the options provided.
Common Use Cases for Hugging Face Datasets
Final Thoughts
Hugging Face has a broad range of datasets available that cater to different natural language processing tasks, from text classification to language modeling. With Hugging Face's growing collection of datasets and consistent updates, it has become a popular and reliable source for NLP data.
These datasets are available for anyone to download and use freely.
More Dataset Listicles: