

Python and R are two of the most popular programming languages used for statistical analysis, data analysis and machine learning. Both languages offer a rich collection of tools and libraries for working with data and are widely used in academia, research and industry. R is more focused on statistical analysis and has a simpler syntax, while Python has versatility, which enables it to have a broader range of applications and libraries.
In this article, we will focus on the Best Pre-Installed R Datasets Commonly Used for Statistical Analysis, including classification, regression analysis, clustering and time series analysis.
Pre-installed datasets are datasets that come with a piece of software or a platform. In R, these datasets provide a convenient way for users to get started with statistical analysis and machine learning without having to spend time searching for or creating their datasets.
Ultimate List of Pre-Installed R Datasets
1. Mtcars
This dataset includes information about various car models and their performance characteristics. The mtcars dataset is also derived from the 1974 Motor Trend US magazine and comprises 32 observations on 11 variables.
The variables include:
-
Mpg - The mpg variable represents miles per gallon (mpg) for the car model.
-
Cyl - The cyl variable represents the number of cylinders in the engine of the car model.
-
Disp - The disp variable represents the displacement of the car model, which is the volume of air and fuel mixture that the engine can compress and burn in one cycle, in cubic inches.
-
Hp - The hp variable represents the gross horsepower of the car model.
-
Drat - The drat variable represents the rear axle ratio of the car model.
-
Wt - The wt variable represents the weight of the car model, in thousands of pounds.
-
Qsec - The qsec variable represents the time taken to cover a quarter-mile distance from a standing start.
-
Vs - The vs variable represents the type of engine (0 = V-shaped, 1 = straight).
-
Am - The am variable represents the type of transmission (0 = automatic, 1 = manual).
-
Gear - The gear represents the number of forward gears in the car model.
-
Carb - The carb variable represents the number of carburettors in the engine of the car model.
The Mtcars dataset can be loaded into R by typing data(mtcars), or it can be downloaded by clicking
2. ChickWeight
The ChickWeight, or chickwts, dataset includes information about the weight of chickens over time. The dataset also has 578 observations on 4 variables.
The variables include:
-
Weight - The weight variable represents the weight of the chicken in grams.
-
Time - The time variable represents the time in days at which the weight was measured.
-
Chick - The chick variable represents the ID of the chicken.
-
Diet - The diet variable represents the type of diet that the chicken was fed during the experiment.
The ChickWeight dataset can be downloaded into R by typing data(ChickWeight), or it can be downloaded by clicking
3. CO2
The CO2 dataset includes measurements of atmospheric carbon dioxide (CO2) concentrations at the Mauna Loa Observatory in Hawaii, taken from March 1958 to December 2001. The dataset also has 468 observations on 2 variables.
The variables include:
-
CO2 - This variable represents the atmospheric CO2 concentration in ppm, as measured at the Mauna Loa Observatory in Hawaii.
-
Plant - This variable represents the type of plant on which the CO2 concentration was measured. There are two types of plants: "Quebec" and "Mississippi."
The CO2 dataset can be downloaded into R by typing data(CO2), or it can be downloaded by clicking
4. Iris
This dataset includes measurements of the sepal length, sepal width, petal length and petal width of 150 iris flowers, which belong to 3 different species: setosa, versicolor and virginica. The iris dataset has 150 rows and 5 columns, which are stored as a dataframe, including a column for the species of each flower.
The variables include:
-
Sepal.Length - The sepal.length represents the length of the sepal in centimetres.
-
Sepal.Width - The sepal.width represents the width of the sepal in centimetres.
-
Petal.Length - The petal.length represents the length of the petal in centimetres.
-
Species - The species variable represents the species of the iris flower, with three possible values: setosa, versicolor and virginica.
The Iris dataset can be loaded into R by typing data(iris), or it can be downloaded by clicking

5. Boston Housing
The Boston Housing dataset includes housing prices and related factors in the Boston area. The dataset was obtained from information collected by the U.S. Census Service concerning housing in the area of Boston, Massachusetts. The dataset also comprises 506 observations on 14 variables.
The variables include:
-
Crim - The crim variable represents the per capita crime rate by town.
-
Zn - The zn variable represents the proportion of residential land zoned for lots over 25,000 sq.ft.
-
Indus - The indus variable represents the proportion of non-retail business acres per town.
-
Chas - The chas variable represents whether the property is located along the Charles River or not.
-
Nox - The nox variable represents the nitrogen oxides concentration (parts per 10 million) in the air.
-
Rm -The rm variable represents the average number of rooms per dwelling.
-
age: This variable represents the proportion of owner-occupied units built prior to 1940.
-
Dis -The dis variable represents the weighted distances to five Boston employment centres.
-
Rad - The rad variable represents the index of accessibility to radial highways.
-
Tax - The tax variable represents the full-value property-tax rate per $10,000.
-
Ptratio - The ptratio variable represents the pupil-teacher ratio by town.
-
Black - The black variable represents the proportion of blacks by town.
-
Lstat - The lstat variable represents the percentage of the lower status of the population.
-
Medv - The medv variable represents the median value of owner-occupied homes in $1000s.
The Boston Housing dataset can be loaded into R by typing data(Boston), or it can be downloaded by clicking
6. Airquality
This dataset includes daily air quality measurements in New York, between May to September 1973. It also consists of 153 observations on 6 variables.
The variables include:
-
Ozone - The ozone variable represents the maximum daily ozone concentration in parts per billion (ppb) measured at a monitoring station in New York.
-
Solar - R: The solar.R variable represents the daily solar radiation in Langleys (a measure of solar energy) measured at the same monitoring station.
-
Wind - The wind variable represents the average daily wind speed in miles per hour (mph).
-
Temp - The temp variable represents the average daily temperature in degrees Fahrenheit.
-
Month - The month variable represents the month in which the observation was made (a value between 5 and 9).
-
Day - The day variable represents the day of the month on which the observation was made (a value between 1 and 31).
The Airquality dataset can be loaded into R by typing data(air quality), or it can be downloaded by clicking
7. Titanic
The Titanic dataset includes information about the passengers aboard the Titanic, which includes whether they survived or not. The dataset also contains 891 rows and 12 variables and is also based on the passenger list of the ill-fated maiden voyage of the Titanic, which sank in the North Atlantic Ocean on April 15th,1912, after colliding with an iceberg.
The variables include:
-
PassengerId - This variable represents the unique identifier for each passenger on the Titanic.
-
Survived - This variable represents whether the passenger survived or not. A value of 0 indicates that the passenger did not survive, while a value of 1 indicates that the passenger did survive.
-
Pclass - This variable represents the passenger's class of travel. There were three classes on the Titanic: first, second, and third.
-
Name - This variable represents the passenger's name.
-
Sex - This variable represents the passenger's gender.
-
Age - This variable represents the passenger's age.
-
SibSp - This variable represents the number of siblings/spouses that the passenger had on board the Titanic.
-
Parch - This variable represents the number of parents/children that the passenger had on board the Titanic.
-
Ticket - This variable represents the ticket number of the passenger.
-
Fare - This variable represents the fare that the passenger paid for their ticket.
-
Cabin - This variable represents the cabin number of the passenger.
-
Embarked - This variable represents the port of embarkation for the passenger. There were three ports of embarkation on the Titanic: Cherbourg, Queenstown, and Southampton.
The Titanic dataset can be loaded into R by typing data(titanic), or it can be downloaded by clicking
8. Faithful
This dataset includes measurements of the eruption and waiting times between eruptions for the Old Faithful geyser in Yellowstone National Park. The Faithful dataset also contains 272 observations on 2 variables.
The variables include:
-
Eruption time - The eruption time variable represents the duration of the current eruption in minutes.
-
Waiting time - The waiting time variable represents the length of time between the current and the previous eruption in minutes.
The Faithful dataset can be loaded into R by typing data(faithful), or it can be downloaded by clicking
9. Orange
The Orange dataset includes growth measurements of orange trees. The dataset also contains 35 observations on 3 variables.
The variables include:
-
Tree - A numeric vector that represents the tree number (1-5).
-
Age - A numeric vector that represents the age of the tree (in years).
-
Circumference - A numeric vector that represents the trunk circumference of the tree (in mm).
The Orange dataset can be loaded into R by typing data(Orange), or it can be downloaded by clicking
10. PlantGrowth
This dataset includes the results of an experiment on the effect of fertilizer on plant growth. The dataset also contains 30 observations on 2 variables.
The variables include:
-
Weight - A numeric vector that represents the weight of plants (in grams).
-
Group - A factor variable that represents the fertilizer treatment group (either "ctrl" for the control group or "trt" for the treated group).
The PlantGrowth dataset can be loaded into R by typing data(PlantGrowth), or it can be downloaded by clicking
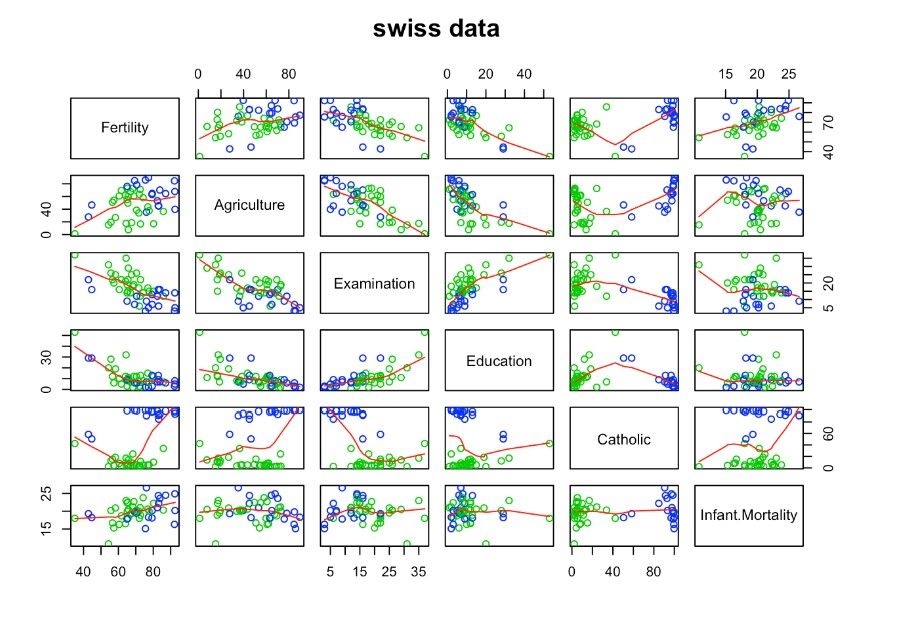
11. Swiss
The Swiss dataset includes socio-economic data for 47 French-speaking provinces of Switzerland during the early 1880s. It also consists of 47 observations across 6 variables.
The variables include:
-
Fertility - This variable represents the fertility rate (number of live births per 1000 women) in each canton.
-
Agriculture - This variable represents the percentage of males in the canton classified as farmers.
-
Examination - This variable represents the percentage of males in the canton who took the military examination.
-
Education - This variable represents the percentage of people in the canton who were educationally qualified to attend university.
-
Catholic - This variable represents the percentage of the population in the canton who are Catholic.
-
Infant.Mortality - This variable represents the infant mortality rate (number of deaths of children under 1 year of age per 1000 live births) in each canton.
The Swiss dataset can be loaded into R by typing data(swiss), or it can be downloaded by clicking
12. Women
This dataset includes the heights of mothers and their daughters for American women aged 30-39. The dataset also consists of 15 observations on 2 variables.
The variables include:
-
Mother - A numeric vector that represents the height of the mother (in inches).
-
Daughter - A numeric vector that represents the height of the daughter (in inches).
The Women dataset can be loaded into R by typing data(women), or it can be downloaded by clicking
Common Use Cases for Pre-Installed R Datasets
Final Thoughts
These datasets can also be accessed through R packages like "tidyverse", "ggplot2" and "data.table”
They are also available in public repositories such as Kaggle, GitHub and the UCI Machine Learning Repository.
The lead image of this article was generated via HackerNoon's AI Stable Diffusion model using the prompt 'R Programming'.
More Dataset Listicles: